你真的了解 CDC 嘛
Change Data Capture 简称 CDC, 用于异构数据同步,将 database 的数据同步到第三方,这里的 DB 可以是 MySQL, PG, Mongo 等等一切数据源,英文技术圈称之为 Single Source OF True (SSOT), 目标称为 Derived Data Systems。常见的使用场景有:
- 缓存 Cache, 异步的生成,删除,更新缓存 kv
- 构建索引,比如将数据同步到 ES 用于全文检索
- 大数据分析 Warehouse, 实时同步数据,离线分析等等
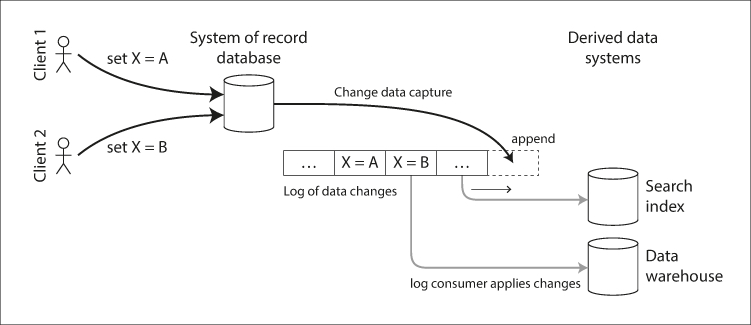
上面的架构图来自 DDIA, 与当年在赶集网时一样:用户发贴,数据写到数据库 MySQL 中,CDC 服务将自己伪装成 slave 从库实时接收 binlog, 解析后更新相应的 memcache 集群
移动互联网十多年发展,CDC 技术理念己经相当成熟,每种语言都有成熟的轮子。当年赶集网使用非常古老的 tungsten replicator, 非常难用,后来迁移到 alibaba 开源的 alibaba canal, 大部份 java 公司都基于 canal 做定制,基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费的产品中,canal 使用是最广最成熟
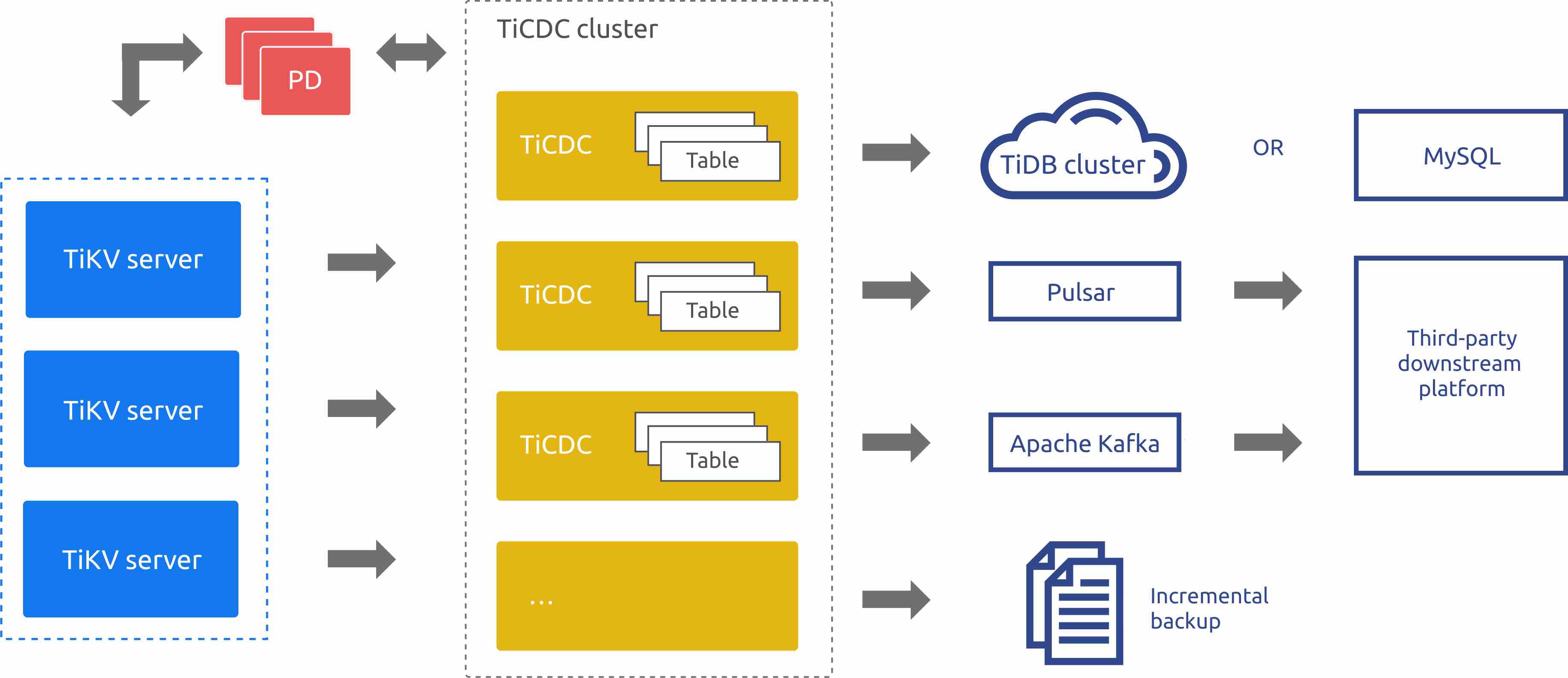
对于 go 技术栈的公司,可以使用 go-mysql 开源项目,创建者是 PingCAP 首架唐刘大佬。非常成熟,使用也最广,包括他们自己的产品 ticdc, 可以同步数据到 MySQL, Puslar, TiDB, Kafka 以及做增量备份
另外这类产品非常考验运维,稳定的产品一般没人在意,出故障就会影响数据一致性
比如删除大批数据, 或是 alter table, 造成 CDC 延迟,那么 cache 更新慢,数据删了但是缓存还有,这种场景需要限速。单点都有高可用问题,需要制定方案,定期演练
原理
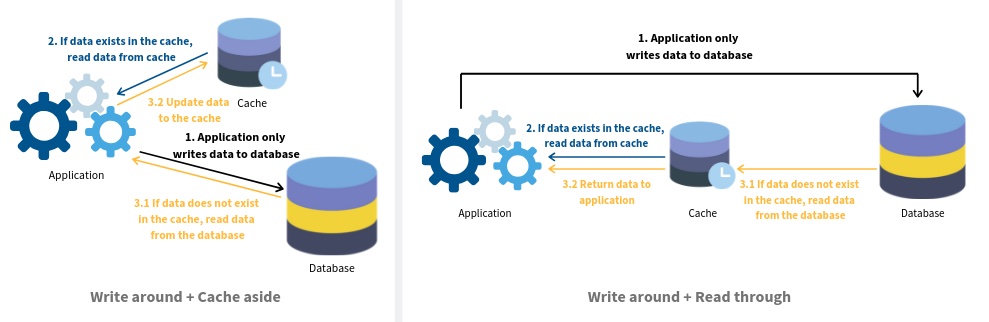
以赶集网更新贴子缓存的例子,如果没有 CDC 服务,程序代码会耦合非常多的双写逻辑,业务自己负责同步数据到缓存,所有涉及 DB 变更的地方都需要写上这段代码,当然也可以放到 DAO 里面
相比于应用层同步,CDC 旁路模式做同步,主要有三种旁路原理:
- 触发器 trigger 将更新通过触发器写到专用表 table, 缺点非常多,性能不好,不能异构写
- 增加 time 字段,数据惰性删除标记 NULL,
CDC服务定期扫该表。缺点实时无法保证,而且对业务有侵入,要求业务适配 - 解析 log, 当前主流实现,Mongodb 读取 oplog, MySQL 读取 binlog
解析 binlog, 增量解析日志可以保证实时性,同时也将逻辑与业务解耦,性能得以保证,业务不用写过多双写代码。新生的 DB,己经原生支持 binlog 或是 transactions 事务事件订阅,类比 go, rust 这些后发语言一样,新特性的支持都是后发优势
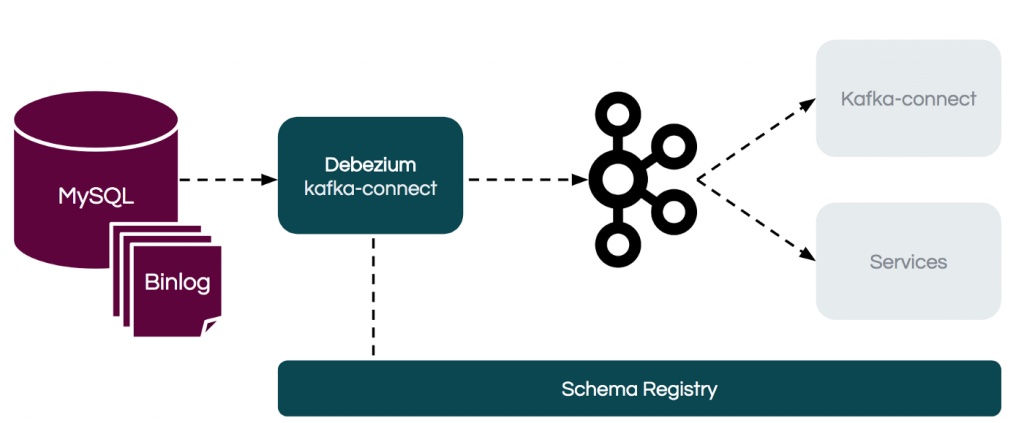
推荐一个 red hat 出品的 Debezium 开源软件,数据源支持 MySQL,MongoDB,PostgreSQL,SQL Server,Oracle,Db2,Cassandra, 通过 kafka connect 获得增量数据写到 kafka, 供后续业务订阅与消费
事务
基于 binlog 解析实现的 CDC 要求 MySQL 开启 row 模式,并且建义 full image 记录全量字段,这点保证了数据更新的 order 顺序,但是没有保证事务的原子性。原因在于 row binlog 是一行行的,同一个事务可能更新多个表或是多行数据,那么要求同一个事务的数据要打包发送到下游,才能保证原子性

同样这也有成熟的解决方案,ringbuffer 等待接收事务所有数据,然后一起提交到消费端。这个也不是万能,只能做到 try best to guarantee, 比如超大事务 batch 更新
FSC
上面提到的 binlog 是持续增量更新,那么如何同步全部基量数据呢?这个术语叫做 Full State Capturue 简称 FSC, 叫啥无所谓 … 方法很多
可以通过 Xtrabackup 备份全量 mysql 数据后,记录下最新的 binlog pos X, 然后回放全量 + 从 X 开始消费
对于一致性要求不严格的场景直接扫 db 就可以,比如半夜定时任务,同到 mysql 数据到 es
相比于 Xtrabackup 比较重的实现,还需要回放数据,比较麻烦。DBLog 论文 提到一种解决方案,比较有意思,大致思路是:不做全量备份,开通时间窗口,在窗口期内通过主键 pk 按 chunk (比如 10 条记录一批)扫表,混合扫表和 binlog 解析出来的数据,去掉冲突的部份,不断重复这个过程,直接全部扫完,这就是 Full State Capture, 让我们看下实现细节
如何定义窗口? 创建一张单独的 meta 表,表内只有一条记录,更新这条记录,此时 binlog 里就会生成此记录,标记为 Low Watermark, 然后 select 选取块数据,最后再更新访表记录,生成一个新的 binlog,标记为 High Watermark. 因为 select 是不会记到 binlog 的,所以只能通过这种方式。那么如何混合 select 块数据和 binlog 增量数据呢?
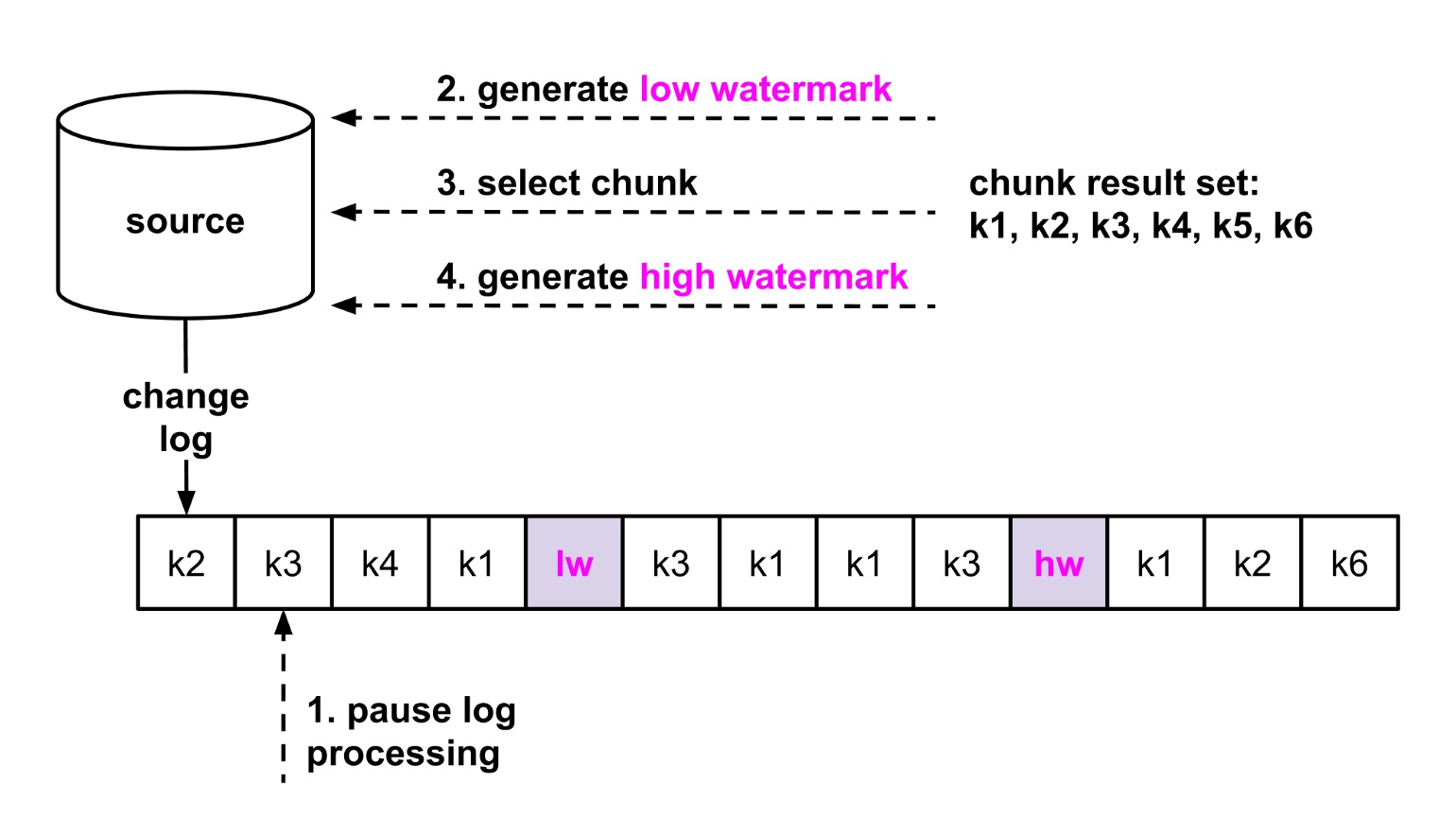
示例中我们有 k1,k2,k3,k4,k5,k6 全量数据,lw 表示低水位,hw 表示高水位的 binlog 位置。change log 也就是 binlog, 在 binlog k3 位置时我们暂停处理的,然后更新 meta 表,生成 lw 低水位,select 选择了所有的 6 条数据,再生成 hw 关闭窗口。最后开启 binlog 数据处理
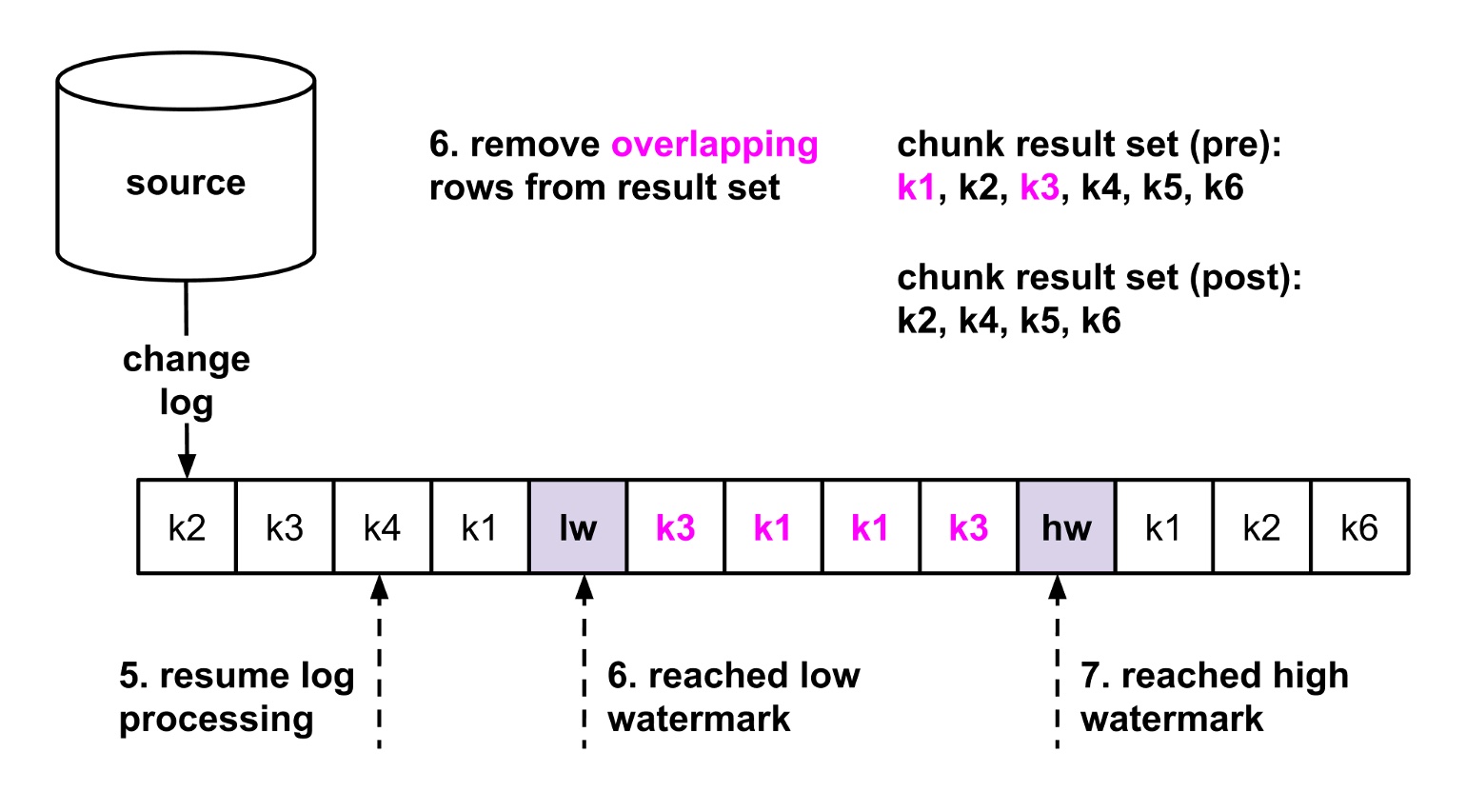
根据 mysql 事务特性,我们可以确定,select 的 6 条数据一定比 lw 前的新,但是窗口期内是不确定的,也就是 lw 到 hw 如果和 select 有重叠的数据,那么是要从 select 的结果中删除的
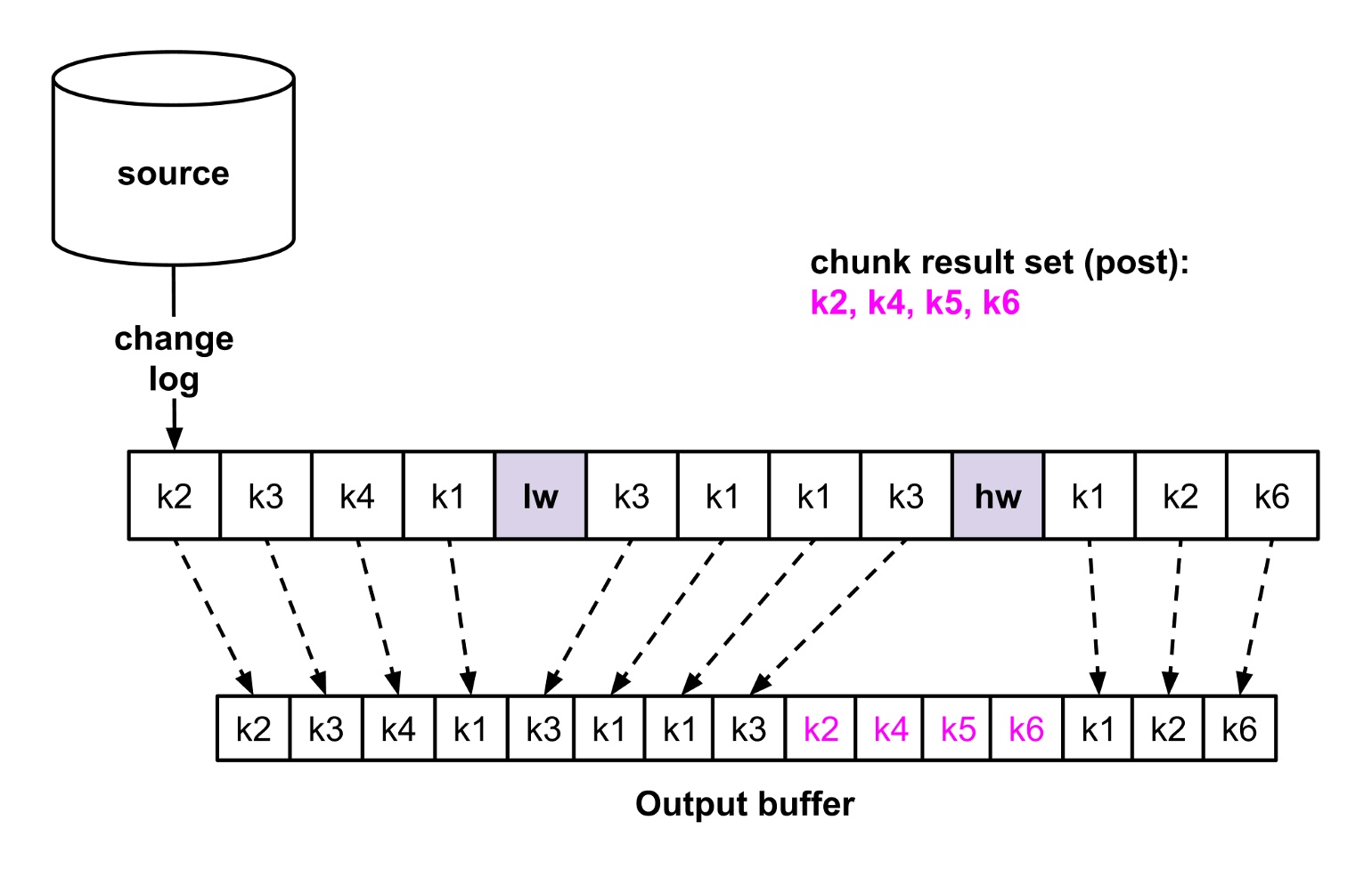
不断重复上述步骤,最终 k2, k4, k5, k6 select 的数据混合进 binlog process 的 output buffer 中。原理不难,这里有个思考题给大家,如果 select 语句与 lw 或是 hw 更新放到同一个事务中,处理会不会更容易?
其它
一致性方面就不要想了,Eventual Consistent 的系统会有时间窗口延迟,尤其是 binlog 解析出来的日志如果要写 kafka, 应用再去订阅消费,更无法保证一致。大概率情况,每天都要重新校验一次全量数据
CDC 服务也要做到高可用的,可以定期将消费的 binlog pos 同步到 zk/etcd 等外部存储,多个 CDC 服务竞争任务。如果是 MySQL 切表的话,需要 CDC 服务也参与,还要区分是否开启 GTID, 各种集群实现。一般为了避免这种情况,CDC 服务都是连接 slave 从库
Schema 变更与映射要看具体 CDC 的实现,动态识别变更,自定义映射,比如 mysql 表与目标结构不一致,create_at 映射成 CreateAt 等等
小结
任何技术都是在特定背景下产生的,pc 时代单体服务大行其道,流量也不大,db 就能服务所有流量,所有数据 join 就可以。移动互联网兴趣后,单体服务,单 db 性能就很差,所以需要解耦,将异构数据同步交给专用的 CDC 服务。当微服务兴起后,数据无法存储在单个表中,分散在不同服务,基于 db 底层技术的 CDC 就显得捉襟见肘,此时 CQRS Command and Query Responsibility Segregation 命令查询分离走进视野,关于 CQRS, Event Sourcing 我们下一篇再介绍
写文章不容易,如果对大家有所帮助和启发,请大家帮忙点击在看,点赞,分享 三连
关于 CDC 大家有什么看法,欢迎留言一起讨论,大牛多留言 ^_^