围观 Roblox 持续三天的故障

Roblox 是一家游戏公司,也是元宇宙概念股。去年底发生一起故障,持续三天之久,官网也发布 blog总结了原因,但并没有说清楚底层 boltdb 的问题。由于需要 FQ, 同时把官方 blog 复制了一份,欢迎围观 https://mytechshares.com/2022/02/16/roblox-return-to-service/
故障原因
一句话总结:Roblox 使用 consul mesh 做服务治理框架,故障前逐步放量启用 stream 功能,consul leader 选举和数据同步存储使用 boltdb, 放量后恰巧触发了 boltdb 性能问题
原因看似简单,但是大型互联网架构本身很复杂,出问题很难第一时间定位原因,无论业务还是基础架构。同时 Roblox 使用 consul 企业版对于公司是黑盒,boltdb 问题也是事后由 hashicorp 公司定位
Boltdb 介绍
Boltdb 性能问题参考 HN 的讨论,修复请参考 阿里巴巴的 Segregated Hashmap Patch
Boltdb 是 LMDB 的移值实现,单机存储引擎里算是比较挫的,目前出名开源软件只有 etcd 在使用,并且原作者 go boltdb 己经废弃 deprecated, 请使用 etcd 的 bboltdb
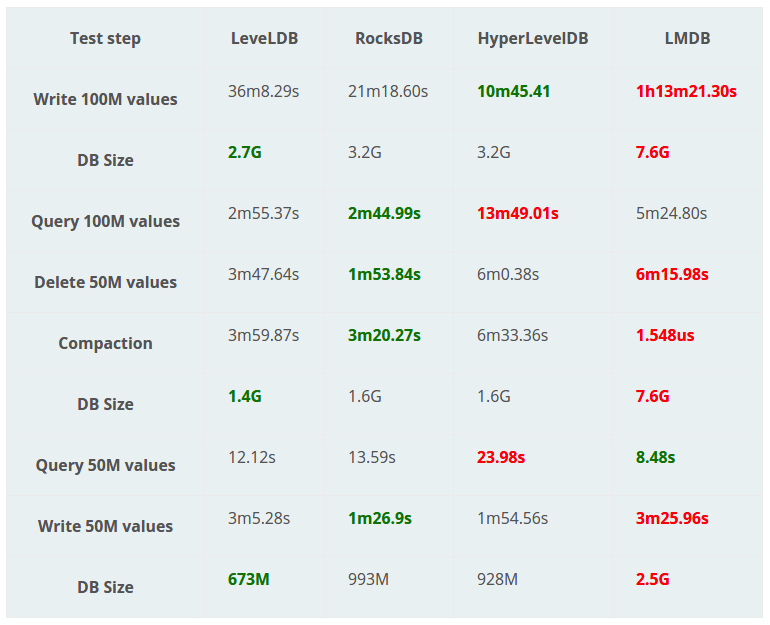
etcd 之所以采用 boltdb, 主要是看中了 boltdb 是 B+tree 实现,支持完整的 ACID, 支持事务。从上图可以看到,性能压测除了 Query 50M values 全是最低的。关于 boltdb 源码分析推荐老C的 boltdb 源码分析系列,我是他二十年老粉
性能问题
Boltdb 只有一个文件,使用 Mmap syscall 映射到内存,并没有使用内存池来管理。磁盘文件以页 Page(4KB) 划分数据单元,当页不在使用时,并不会释放磁盘空间,而是使用 freelist 维护空闲列表,供后续使用
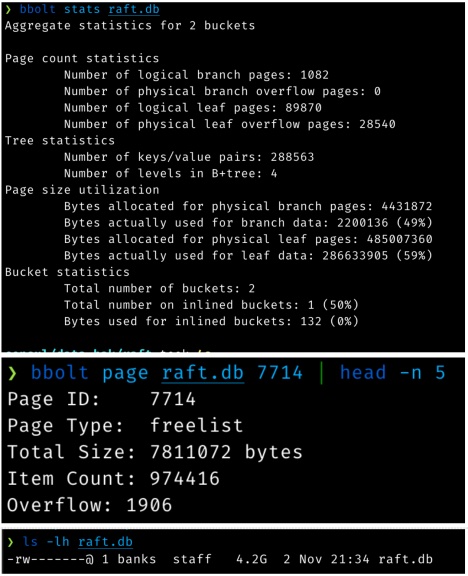
上图是 Roblox 公司的数据统计,4G 大小的文件,大部分都是空闲的并未使用。性能问题就在于每次 B+tree 调整,分配,释放页时,arrayAllocate算法复杂度都是 O(n)
1 | func (f *freelist) arrayAllocate(txid txid, n int) pgid { |
该代码用于从 freelist 列表 ids 数组中,寻找连续空闲的 n 页 Page, 当 boltdb 中有大量空闲页且不满足需求时,都会线性遍历全部列表,即使找到了,也要有大量的数组移动,性能影响很大
2019 年时阿里巴巴的 chenxingyu 同学调研并提交了修复 segregated hashmap patch, 使得 boltdb 文件大小增长到 100G 也无性能衰减,Roblox 最后修复故障也是使用了这个 patch
新算法原理也很简单,大家刷 leetcode 都知道 TwoSum 算法吧?本质也是空间换时间,通过构建多个 map, 索引空闲列表长度与 Page id 对应关系。使得复杂度由 O(n) 变成 O(1)
1 | // pidSet holds the set of starting pgids which have the same span size |
主要是增加三个 Map
freemapskey 是连续空闲页的长度,value 是 Page id 集合forwardMap前向 map, key 是 start pgid, value 是连续空闲长度,比如 pgid 101, value 是 3, 那么代表 [101,102,103] 均空闲backwardMap后向 map, 道理一样,key 是 end pgid, value 是连续长度,比如 pgid 101, value 是 3, 那么代表 [99,100,101] 均空闲
1 | // mergeWithExistingSpan merges pid to the existing free spans, try to merge it backward and forward |
mergeWithExistingSpan 用于尽可能合并空闲页 pid, 代码很简单,分别查找 backwardMap, forwardMap 如果相邻,那么就尽可能合并
1 | func (f *freelist) addSpan(start pgid, size uint64) { |
addSpan, delSpan 复杂度均为 O(1)
1 | // hashmapAllocate serves the same purpose as arrayAllocate, but use hashmap as backend |
hashmapAllocate 用于申请连续空闲的 n 页,复杂度是 O(1), 也有可能退化成 O(n) 去遍历 freemaps, 从大于 n 页的列表中申请
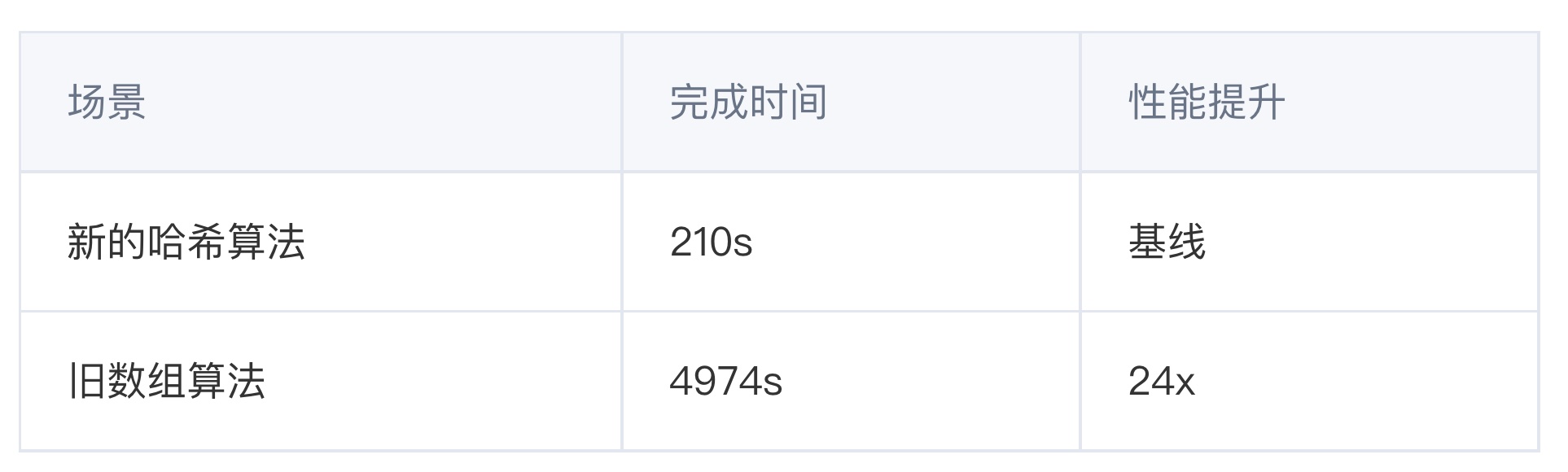
性能测试来自 alibaba blog
评价一下
墨菲定律:如果事情有变坏的可能,不管这种可能性有多小,它总会发生。Roblox 故障持续三天,说明大规模互联网 IT 建设本身非常难,平时就需要做好演练,一切可能成为瓶颈的组件,一定会出问题
Etcd 2019 年这个问题就 FIX 了,但是 consul 并没有 port 修复,基础架构从业者还是要多关注 bug fix
服务发现是最核心的组件,无论使用 etcd, 还是 consul mesh, 本质还是一个 CP 系统,使用 raft 来确保数据一致性,但我们真的要求强一致嘛?答案肯定是否定的,国内大公司很少直接用,更多的是强调可用性
可观测性,随随变变上百个微服务,如果没有构建好监控报警系统,出故障很难定位问题。大家在做项目时也要注意这一点
小结
写文章不容易,如果对大家有所帮助和启发,请大家帮忙点击在看,点赞,分享 三连
关于 boltdb 大家有什么看法,欢迎留言一起讨论,大牛多留言 ^_^
