Roblox Return to Service 10_28-10_31 2021
版权归 Roblox 所有,方便大家免 FQ 查看,复制在此。原文地址:https://blog.roblox.com/2022/01/roblox-return-to-service-10-28-10-31-2021/
Starting October 28th and fully resolving on October 31st, Roblox experienced a 73-hour outage.1 Fifty million players regularly use Roblox every day and, to create the experience our players expect, our scale involves hundreds of internal online services. As with any large-scale service, we have service interruptions from time to time, but the extended length of this outage makes it particularly noteworthy. We sincerely apologize to our community for the downtime.
issues from happening in the future. We would like to reiterate there was no user data loss or access by unauthorized parties of any information during the incident.
Roblox Engineering and technical staff from HashiCorp combined efforts to return Roblox to service. We want to acknowledge the HashiCorp team, who brought on board incredible resources and worked with us tirelessly until the issues were resolved.
Outage Summary
The outage was unique in both duration and complexity. The team had to address a number of challenges in sequence to understand the root cause and bring the service back up.
- The outage lasted 73 hours.
- The root cause was due to two issues. Enabling a relatively new streaming feature on Consul under unusually high read and write load led to excessive contention and poor performance. In addition, our particular load conditions triggered a pathological performance issue in BoltDB. The open source BoltDB system is used within Consul to manage write-ahead-logs for leader election and data replication.
- A single Consul cluster supporting multiple workloads exacerbated the impact of these issues.
- Challenges in diagnosing these two primarily unrelated issues buried deep in the Consul implementation were largely responsible for the extended downtime.
- Critical monitoring systems that would have provided better visibility into the cause of the outage relied on affected systems, such as Consul. This combination severely hampered the triage process.
- We were thoughtful and careful in our approach to bringing Roblox up from an extended fully-down state, which also took notable time.
- We have accelerated engineering efforts to improve our monitoring, remove circular dependencies in our observability stack, as well as accelerating our bootstrapping process.
- We are working to move to multiple availability zones and data centers.
- We are remediating the issues in Consul that were the root cause of this event.
HashiStack
Roblox’s core infrastructure runs in Roblox data centers. We deploy and manage our own hardware, as well as our own compute, storage, and networking systems on top of that hardware. The scale of our deployment is significant, with over 18,000 servers and 170,000 containers.
In order to run thousands of servers across multiple sites, we leverage a technology suite commonly known as the “HashiStack.” Nomad, Consul and Vault are the technologies that we use to manage servers and services around the world, and that allow us to orchestrate containers that support Roblox services.
Nomad is used for scheduling work. It decides which containers are going to run on which nodes and on which ports they’re accessible. It also validates container health. All of this data is relayed to a Service Registry, which is a database of IP:Port combinations. Roblox services use the Service Registry to find one another so they can communicate. This process is called “service discovery.” We use Consul for service discovery, health checks, session locking (for HA systems built on-top), and as a KV store.
Consul is deployed as a cluster of machines in two roles. “Voters” (5 machines) authoritatively hold the state of the cluster; “Non-voters” (5 additional machines) are read-only replicas that assist with scaling read requests. At any given time, one of the voters is elected by the cluster as leader. The leader is responsible for replicating data to the other voters and determining if written data has been fully committed. Consul uses an algorithm called Raft for leader election and to distribute state across the cluster in a way that ensures each node in the cluster agrees upon the updates. It is not uncommon for the leader to change via leader election several times throughout a given day.
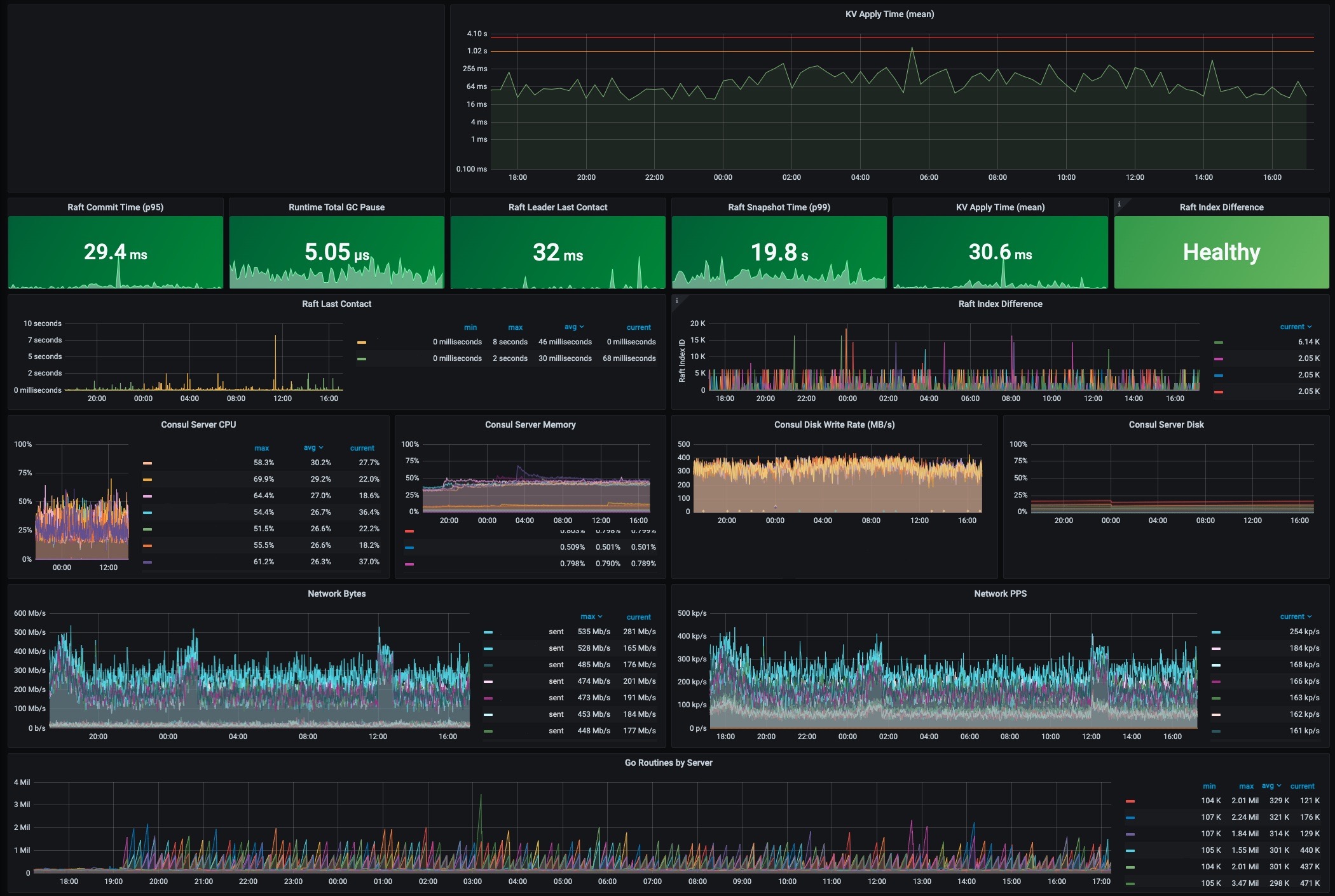
The following is a recent screenshot of a Consul dashboard at Roblox after the incident. Many of the key operational metrics referenced in this blog post are shown at normal levels. KV Apply time for instance is considered normal at less than 300ms and is 30.6ms in this moment. The Consul leader has had contact with other servers in the cluster in the last 32ms, which is very recent.
In the months leading up to the October incident, Roblox upgraded from Consul 1.9 to Consul 1.10 to take advantage of a new streaming feature. This streaming feature is designed to significantly reduce the CPU and network bandwidth needed to distribute updates across large-scale clusters like the one at Roblox.
Initial Detection (10/28 13:37)
On the afternoon of October 28th, Vault performance was degraded and a single Consul server had high CPU load. Roblox engineers began to investigate. At this point players were not impacted.
Early Triage (10/28 13:37 – 10/29 02:00)
The initial investigation suggested that the Consul cluster that Vault and many other services depend on was unhealthy. Specifically, the Consul cluster metrics showed Hardware issues are not unusual at Roblox’s scale, and Consul can survive hardware failure. However, if hardware is merely slow rather than failing, it can impact overall Consul performance. In this case, the team suspected degraded hardware performance as the root cause and began the process of replacing one of the Consul cluster nodes. This was our first attempt at diagnosing the incident. Around this time, staff from HashiCorp joined Roblox engineers to help with diagnosis and remediation. All references to “the team” and “the engineering team” from this point forward refer to both Roblox and HashiCorp staff.
Even with new hardware, Consul cluster performance continued to suffer. At 16:35, the number of online players dropped to 50% of normal.
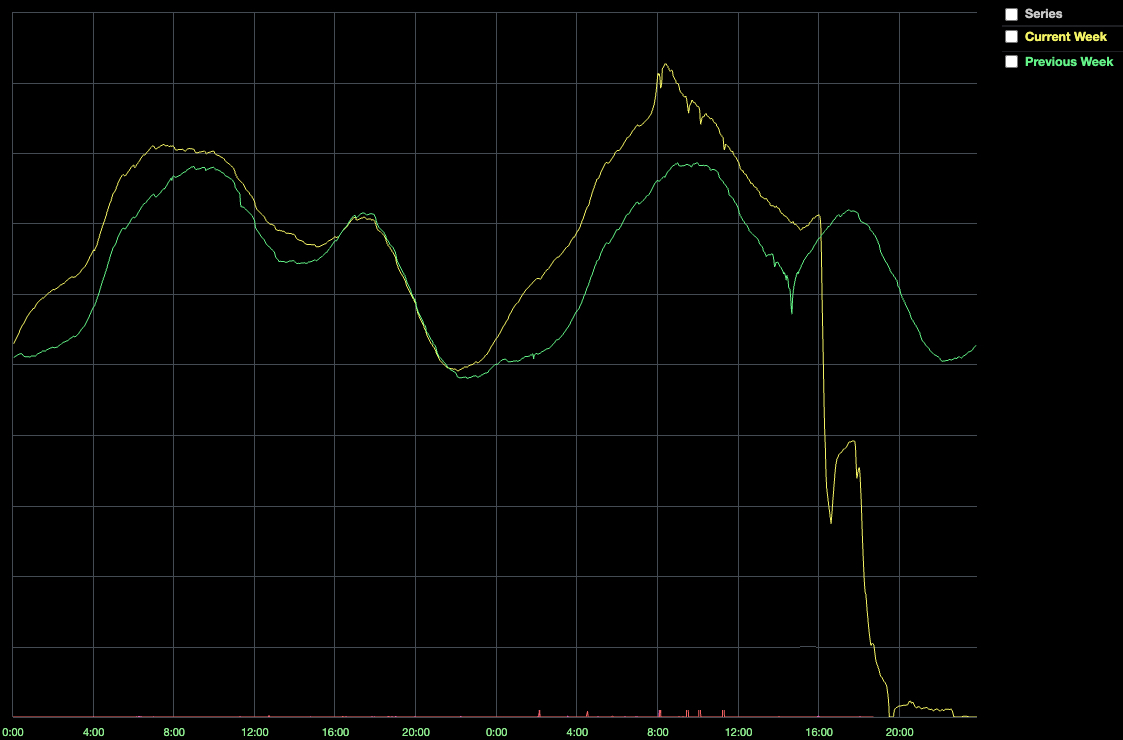
This drop coincided with a significant degradation in system health, which ultimately resulted in a complete system outage. Why? When a Roblox service wants to talk to another service, it relies on Consul to have up-to-date knowledge of the location of the service it wants to talk to. However, if Consul is unhealthy, servers struggle to connect. Furthermore, Nomad and Vault rely on Consul, so when Consul is unhealthy, the system healthy.
At this point, the team developed a new theory about what was going wrong: increased traffic. Perhaps Consul was slow because our system reached a tipping point, and the servers on which Consul was running could no longer handle the load? This was our second attempt at diagnosing the root cause of the incident.
Given the severity of the incident, the team decided to replace all the nodes in the Consul cluster with new, more powerful machines. These new machines had 128 cores (a 2x increase) and newer, faster NVME SSD disks. By 19:00, the team migrated most of the cluster to the new machines but the cluster was still not healthy. The cluster was reporting that a majority of nodes were not able to keep up with writes, and the 50th percentile latency on KV writes was still around 2 seconds rather than the typical 300ms or less.
Return to Service Attempt #1 (10/29 02:00 – 04:00)
The first two attempts to return the Consul cluster to a healthy state were unsuccessful. We could still see elevated KV write latency as well as a new inexplicable symptom that we could not explain: the Consul leader was regularly out of sync with the other voters.
The team decided to shut down the entire Consul cluster and reset its state using a snapshot from a few hours before – the beginning of the outage. We understood that this would potentially incur a small amount of system config data loss (not user data loss). Given the severity of the outage and our confidence that we could restore this system config data by hand if needed, we felt this was acceptable.
We expected that restoring from a snapshot taken when the system was healthy would bring the cluster into a healthy state, but we had one additional concern. Even though Roblox did not have any user-generated traffic flowing through the system at this point, internal Roblox services were still live and dutifully reaching out to Consul to learn the location of their dependencies and to update their health information. These reads and writes were generating a significant load on the cluster. We were worried that this load might immediately push the cluster back into an unhealthy state even if the cluster reset
was successful. To address this concern, we configured iptables on the cluster to block access. This would allow us to bring the cluster back up in a controlled way and help us understand if the load we were putting on Consul independent of user traffic was part of the problem.
The reset went smoothly, and initially, the metrics looked good. When we removed the iptables block, the service discovery and health check load from the internal services returned as expected. However, Consul performance began to degrade again, and eventually we were back to where we started: 50th percentile on KV write operations was back at 2 seconds. Services that depended on Consul were starting to mark themselves “unhealthy,” and eventually, the system fell back into the now-familiar problematic state. It was now 04:00. There was clearly something about our load on Consul that was causing problems, and over 14 hours into the incident, we still didn’t know what it was.
Return to Service Attempt #2 (10/29 04:00 – 10/30 02:00)
We had ruled out hardware failure. Faster hardware hadn’t helped and, as we learned later, potentially hurt stability. Resetting Consul’s internal state hadn’t helped either. There was no user traffic coming in, yet Consul was still slow. We had leveraged iptables to let traffic back into the cluster slowly. Was the cluster simply getting pushed back into an unhealthy state by the sheer volume of thousands of containers trying to reconnect? This was our third attempt at diagnosing the root cause of the incident.
The engineering team decided to reduce Consul usage and then carefully and systematically reintroduce it. To ensure we had a clean starting point, we also blocked remaining external traffic. We assembled an exhaustive list of services that use Consul and rolled out config changes to disable all non-essential usage. This process took several hours due to the wide variety of systems and config change types targeted. Roblox services that typically had hundreds of instances running were scaled down to single digits. Health check frequency was decreased from 60 seconds to 10 minutes to give the cluster additional breathing room. At 16:00 on Oct 29th, over 24 hours after the start of the outage, the team began its second attempt to bring Roblox back online. Once again, the initial phase of this restart attempt looked good, but by 02:00 on Oct 30th, Consul was again in an unhealthy state, this time with significantly less load from the Roblox services that depend on it.
team again pivoted. Instead of looking at Consul from the perspective of the Roblox services that depend on it, the team started looking at Consul internals for clues.
Research Into Contention (10/30 02:00 – 10/30 12:00)
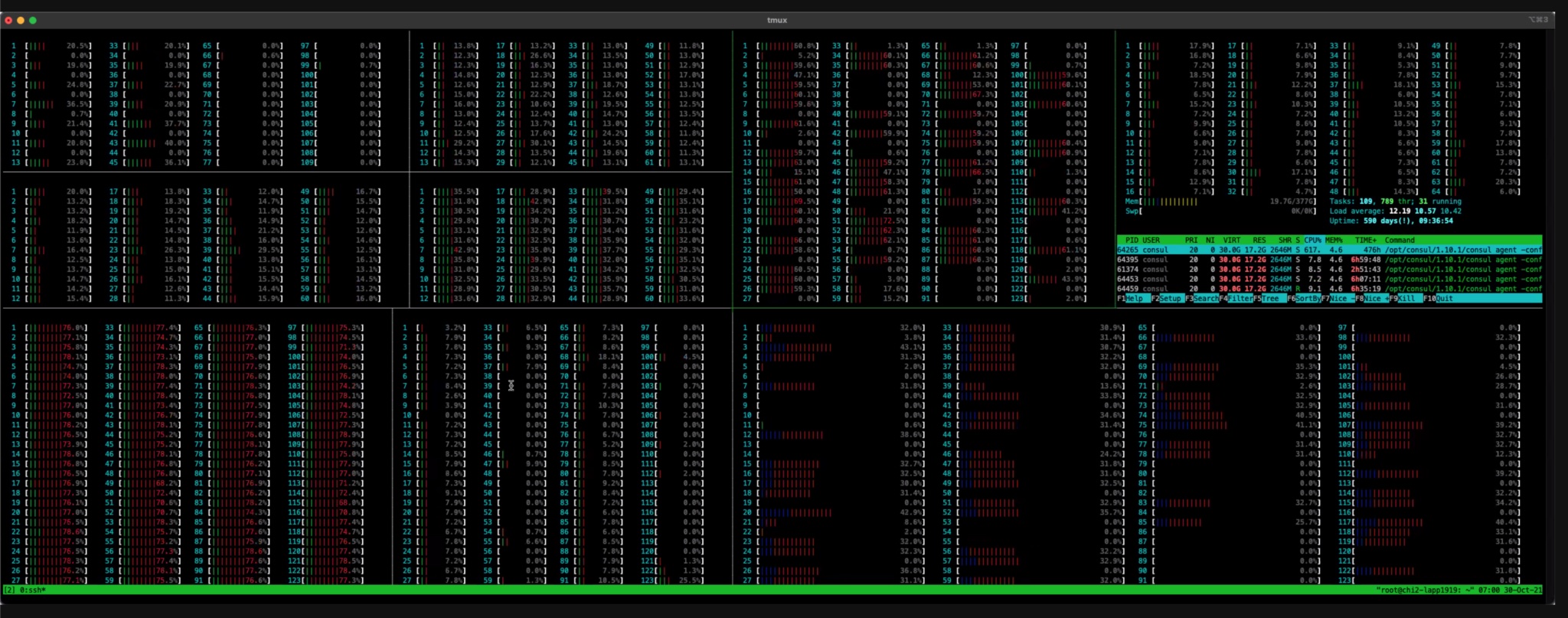
Over the next 10 hours, the engineering team dug deeper into debug logs and operating system-level metrics. This data showed Consul KV writes getting blocked for long periods of time. In other words, “contention.”The cause of the contention was not immediately obvious, but one theory was that the shift from 64 to 128 CPU Core servers early in the outage might have made the problem worse. After looking at the htop data and performance debugging data shown in the screenshots below, the team concluded that it was worth going back to 64 Core servers similar to those used before the outage. The team began to prep the hardware: Consul was installed, operating system configurations triple checked, and the machines readied for service in as detailed a manner as possible. The team then transitioned the Consul cluster back to 64 CPU Core servers, but this change did not help. This was our fourth attempt at diagnosing the root cause of the incident.
Root Causes Found (10/30 12:00 – 10/30 20:00)
Several months ago, we enabled a new Consul streaming feature on a subset of our services. This feature, designed to lower the CPU usage and network bandwidth of the Consul cluster, worked as expected, so over the next few months we incrementally enabled the feature on more of our backend services. On October 27th at 14:00, one day before the outage, we enabled this feature on a backend service that is responsible for traffic routing. As part of this rollout, in order to prepare for the increased traffic we typically see at the end of the year, we also increased the number of nodes supporting traffic routing by 50%. The system had worked well with streaming at this level for a day before the incident started, so it wasn’t initially clear why it’s performance had changed. However through analysis of perf reports and flame graphs from Consul servers, we saw evidence of streaming code paths being responsible for the contention causing high CPU usage. We disabled the streaming feature for all Consul systems, including the traffic routing nodes. The config change finished propagating at 15:51, at which time the 50th percentile for Consul KV writes lowered to 300ms. We finally had a breakthrough.
than long polling. Under very high load – specifically, both a very high read load and a very high write load – the design of streaming exacerbates the amount of contention on a single Go channel, which causes blocking during writes, making it significantly less efficient. This behavior also explained the effect of higher core-count servers: those servers were dual socket architectures with a NUMA memory model. The additional contention on shared resources thus got worse under this architecture. By turning off streaming, we dramatically improved the health of the Consul cluster.
Despite the breakthrough, we were not yet out of the woods. We saw Consul intermittently electing new cluster leaders, which was normal, but we also saw some leaders exhibiting the same latency problems we saw before we disabled streaming, which was not normal. Without any obvious clues pointing to the root cause of the slow leader problem, and with evidence that the cluster was healthy as long as certain servers were not elected as the leaders, the team made the pragmatic decision to work around the problem by preventing the problematic leaders from staying elected. This enabled the team to focus on returning the Roblox services that rely on Consul to a healthy state.
But what was going on with the slow leaders? We did not figure this out during the incident, but HashiCorp engineers determined the root cause in the days after the outage. Consul uses a popular open-source persistence library named BoltDB to store Raft logs. It is not used to store the current state within Consul, but rather a rolling log of the operations being applied. To prevent BoltDB from growing indefinitely, Consul regularly performs snapshots. The snapshot operation writes the current state of Consul to disk and then deletes the oldest log entries from BoltDB.
However, due to the design of BoltDB, even when the oldest log entries are deleted, the space BoltDB uses on disk never shrinks. Instead, all the pages (4kb segments within the file) that were used to store deleted data are instead marked as “free” and re-used for subsequent writes. BoltDB tracks these free pages in a structure called its “freelist.” Typically, write latency is not meaningfully impacted by the time it takes to update the freelist, but Roblox’s workload exposed a pathological performance issue in BoltDB that made freelist maintenance extremely expensive.
It had been 54 hours since the start of the outage. With streaming disabled and a process in place to prevent slow leaders from staying elected, Consul was now consistently stable. The team was ready to focus on a return to service.
Roblox uses a typical microservices pattern for its backend. At the bottom of the microservices “stack” are databases and caches. These databases were unaffected by the outage, but the caching system, which regularly handles 1B requests-per-second across its multiple layers during regular system operation, was unhealthy. Since our caches store transient data that can easily repopulate from the underlying databases, the easiest way to bring the caching system back into a healthy state was to redeploy it.
The cache redeployment process ran into a series of issues:
- Likely due to the Consul cluster snapshot reset that had been performed earlier on, internal scheduling data that the cache system stores in the Consul KV were incorrect.
- Deployments of small caches were taking longer than expected to deploy, and deployments of large caches were not finishing. It turned out that there was an unhealthy node that the job scheduler saw as completely open rather than unhealthy. This resulted in the job scheduler attempting to aggressively schedule cache jobs on this node, which failed because the node was unhealthy.
- The caching system’s automated deployment tool was built to support incremental adjustments to large scale deployments that were already handling traffic at scale, not iterative attempts to bootstrap a large cluster from scratch.
The team worked through the night to identify and address these issues, ensure cache systems were properly deployed, and verify correctness. At 05:00 on October 31, 61 hours since the start of the outage, we had a healthy Consul cluster and a healthy caching system. We were ready to bring up the rest of Roblox.
The Return of Players (10/31 05:00 – 10/31 16:00)
initial outage or the troubleshooting phases. The team needed to restart these services at correct capacity levels and verify that they were functioning correctly. This went smoothly, and by 10:00, we were ready to open up to players.
With cold caches and a system we were still uncertain about, we did not want a flood of traffic that could potentially put the system back into an unstable state. To avoid a flood, we used DNS steering to manage the number of players who could access Roblox. This allowed us to let in a certain percentage of randomly selected players while others continued to be redirected to our static maintenance page. Every time we increased the percentage, we checked database load, cache performance, and overall system stability. Work continued throughout the day, ratcheting up access in roughly 10% increments. We enjoyed seeing some of our most dedicated players figure out our DNS steering scheme and start exchanging this information on Twitter so that they could get “early” access as we brought the service back up. At 16:45 Sunday, 73 hours after the start of the outage, 100% of players were given access and Roblox was fully operational.
Further Analysis and Changes Resulting from the Outage
While players were allowed to return to Roblox on October 31st, Roblox and HashiCorp continued refining their understanding of the outage throughout the following week. Specific contention issues in the new streaming protocol were identified and isolated. While HashiCorp had benchmarked streaming at similar scale to Roblox usage, they had not observed this specific behavior before due to it manifesting from a combination of both a large number of streams and a high churn rate. The HashiCorp engineering team is creating new laboratory benchmarks to reproduce the specific contention issue and performing additional scale tests. HashiCorp is also working to improve the design of the streaming system to avoid contention under extreme load and ensure stable performance in such conditions.
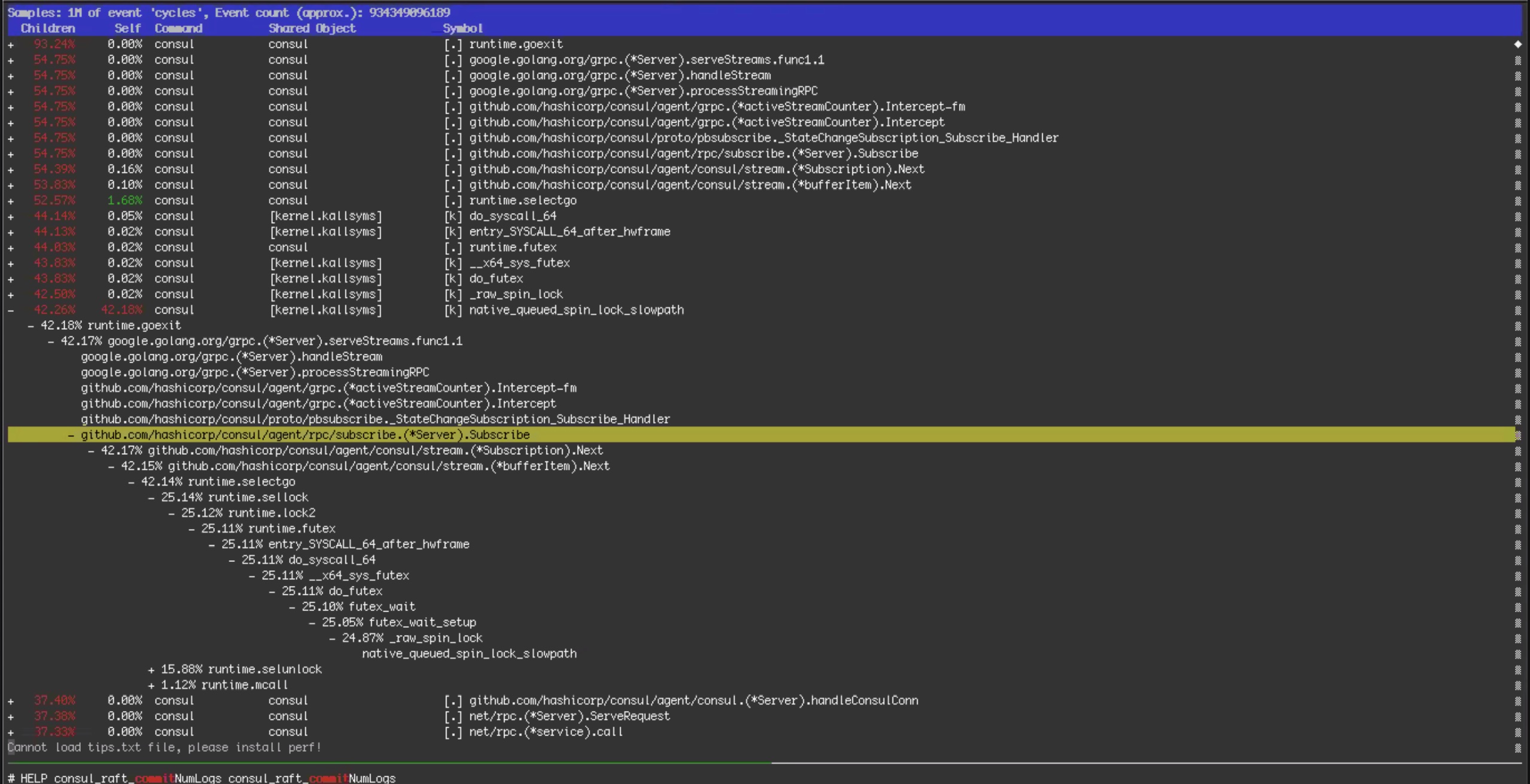
Further analysis of the slow leader problem also uncovered the key cause of the two- second Raft data writes and cluster consistency issues. Engineers looked at flame graphs like the one below to get a better understanding of the inner workings of BoltDB.

As previously mentioned, Consul uses a persistence library called BoltDB to store Raft log data. Due to a specific usage pattern created during the incident, 16kB write operations were instead becoming much larger. You can see the problem illustrated in these screenshots:
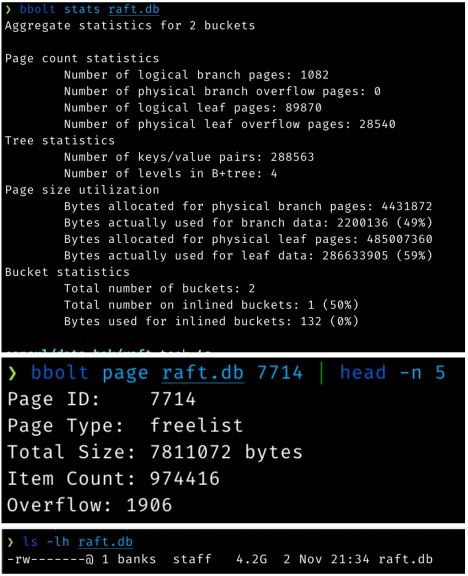
The preceding command output tells us a number of things:
- This 4.2GB log store is only storing 489MB of actual data (including all the index internals). 3.8GB is “empty” space.
- The freelist is 7.8MB since it contains nearly a million free page ids.
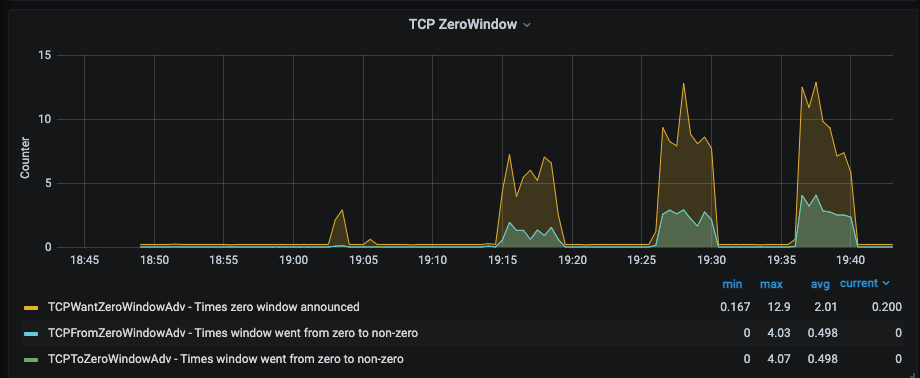
Back pressure on these operations also created full TCP buffers and contributed to 2-3s write times on unhealthy leaders. The image below shows research into TCP Zero Windows during the incident.
HashiCorp and Roblox have developed and deployed a process using existing BoltDB tooling to “compact” the database, which resolved the performance issues.
Recent Improvements and Future Steps
It has been 2.5 months since the outage. What have we been up to? We used this time to learn as much as we could from the outage, to adjust engineering priorities based on what we learned, and to aggressively harden our systems. One of our Roblox values is Respect The Community, and while we could have issued a post sooner to explain what happened, we felt we owed it to you, our community, to make significant progress on improving the reliability of our systems before publishing.
Telemetry Improvements
There was a circular dependency between our telemetry systems and Consul, which meant that when Consul was unhealthy, we lacked the telemetry data that would have made it easier for us to figure out what was wrong. We have removed this circular dependency. Our telemetry systems no longer depend on the systems that they are configured to monitor.
We have extended our telemetry systems to provide better visibility into Consul and BoltDB performance. We now receive highly targeted alerts if there are any signs that the system is approaching the state that caused this outage. We have also extended our telemetry systems to provide more visibility into the traffic patterns between Roblox services and Consul. This additional visibility into the behavior and performance of our system at multiple levels has already helped us during system upgrades and debugging sessions.
Expansion Into Multiple Availability Zones and Data Centers
Running all Roblox backend services on one Consul cluster left us exposed to an outage of this nature. We have already built out the servers and networking for an additional, geographically distinct data center that will host our backend services. We have efforts underway to move to multiple availability zones within these data centers; we have made major modifications to our engineering roadmap and our staffing plans in order to accelerate these efforts.
Consul Upgrades and Sharding
Roblox is still growing quickly, so even with multiple Consul clusters, we want to reduce the load we place on Consul. We have reviewed how our services use Consul’s KV store and health checks, and have split some critical services into their own dedicated clusters, reducing load on our central Consul cluster to a safer level.
Some core Roblox services are using Consul’s KV store directly as a convenient place to store data, even though we have other storage systems that are likely more appropriate.
We discovered a large amount of obsolete KV data. Deleting this obsolete data improved Consul performance.
We are working closely with HashiCorp to deploy a new version of Consul that replaces BoltDB with a successor called bbolt that does not have the same issue with unbounded freelist growth. We intentionally postponed this effort into the new year to avoid a complex upgrade during our peak end-of-year traffic. The upgrade is being tested now and will complete in Q1.
Improvements To Bootstrapping Procedures and Config Management
The return to service effort was slowed by a number of factors, including the deployment and warming of caches needed by Roblox services. We are developing new tools and processes to make this process more automated and less error-prone. In particular, we have redesigned our cache deployment mechanisms to ensure we can quickly bring up our cache system from a standing start. Implementation of this is underway.
We worked with HashiCorp to identify several Nomad enhancements that will make it easier for us to turn up large jobs after a long period of unavailability. These enhancements will be deployed as part of our next Nomad upgrade, scheduled for later this month.
We have developed and deployed mechanisms for faster machine configuration changes.
Reintroduction of Streaming
We originally deployed streaming to lower the CPU usage and network bandwidth of the Consul cluster. Once a new implementation has been tested at our scale with our workload, we expect to carefully reintroduce it to our systems.
A Note on Public Cloud
Another one of our Roblox values is Take The Long View, and this value heavily informs our decision-making. We build and manage our own foundational infrastructure on-prem because, at our current scale, and more importantly, the scale that we know we’ll reach as our platform grows, we believe it’s the best way to support our business and our community. Specifically, by building and managing our own data centers for backend and network edge services, we have been able to significantly control costs compared to public cloud. These savings directly influence the amount we are able to pay to creators on the platform. Furthermore, owning our own hardware and building our own edge infrastructure allows us to minimize performance variations and carefully manage the latency of our players around the world. Consistent performance and low latency are critical to the experience of our players, who are not necessarily located near the data centers of public cloud providers.
Note that we are not ideologically wedded to any particular approach: we use public cloud for use cases where it makes the most sense for our players and developers. As examples, we use public cloud for burst capacity, large portions of our DevOps workflows, and most of our in-house analytics. In general we find public cloud to be a good tool for applications that are not performance and latency critical, and that run at a limited scale. However, for our most performance and latency critical workloads, we have made the choice to build and manage our own infrastructure on-prem. We made this choice knowing that it takes time, money, and talent, but also knowing that it will allow us to build a better platform. This is consistent with our Take The Long View value.
System Stability Since The Outage
Roblox typically receives a surge of traffic at the end of December. We have a lot more reliability work to do, but we are pleased to report that Roblox did not have a single significant production incident during the December surge, and that the performance and stability of both Consul and Nomad during this surge were excellent. It appears that our immediate reliability improvements are already paying off, and as our longer term projects wrap up we expect even better results.
We want to thank our global Roblox community for their understanding and support. Another one of our Roblox values is Take Responsibility, and we take full responsibility for what happened here. We would like to once again extend our heartfelt thanks to the team at HashiCorp. Their engineers jumped in to assist us at the outset of this unprecedented outage and did not leave our side. Even now, with the outage two months behind us, Roblox and HashiCorp engineers continue to collaborate closely to ensure we’re collectively doing everything we can to prevent a similar outage from ever happening again.
Finally, we want to thank our Roblox colleagues for validating why this is an amazing place to work. At Roblox we believe in civility and respect. It’s easy to be civil and respectful when things are going well, but the real test is how we treat one another when things get difficult. At some point during a 73-hour outage, with the clock ticking and the stress building, it wouldn’t be surprising to see someone lose their cool, say something disrespectful, or wonder aloud whose fault this all was. But that’s not what happened. We supported one another, and we worked together as one team around the clock until the service was healthy. We are, of course, not proud of this outage and the impact it had on our community, but we are proud of how we came together as a team to bring Roblox back to life, and how we treated each other with civility and respect at every step along the way.
We have learned tremendously from this experience, and we are more committed than ever to make Roblox a stronger and more reliable platform going forward.
Thank you again.