阅读 redis 源码,学习缓存淘汰算法 W-TinyLFU

所有 IT 从业者都接触过缓存,一定了解基本工作原理,业界流行一句话:缓存就是万金油,哪里有问题哪里抹一下。那他的本质是什么呢?
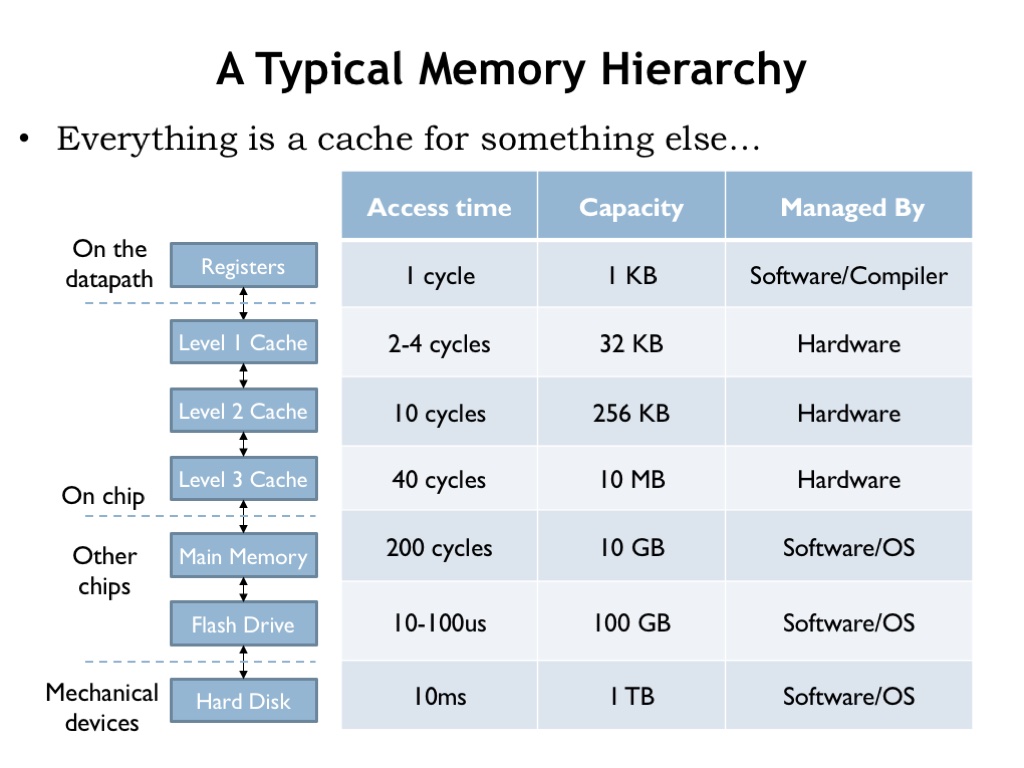
上图代表从 cpu 到底层硬盘不同层次,不同模块的运行速度,上层多加一层 cache, 就能解决下层的速度慢的问题,这里的慢是指两点:IO 慢和 cpu 重复计算缓存中间结果
但是 cache 受限于成本,cache size 一般都是固定的,所以数据需要淘汰,由此引出一系列其它问题:缓存一致性、击穿、雪崩、污染等等,本文通过阅读 redis 源码,学习主流淘汰算法
如果不是 leetcode 146 LRU 刷题需要,我想大家也不会手写 cache, 简单的实现和工程实践相距十万八千里,真正 production ready 的缓存库非常考验细节
Redis 缓存淘汰配置
一般 redis 不建义当成存储使用,只允许当作 cache, 并设置 max-memory, 当内存使用达到最大值时,redis-server 会根据不同配置开始删除 keys. Redis 从 4.0 版本引进了 LFU, 即 Least Frequently Used,4.0 以前默认使用 LRU 即 Least Recently Used
- volatile-lru 只针对设置 expire 过期的 key 进行 lru 淘汰
- allkeys-lru 对所有的 key 进行 lru 淘汰
- volatile-lfu 只针对设置 expire 过期的 key 进行 lfu 淘汰
- allkeys-lfu 对所有的 key 进行 lfu 淘汰
- volatile-random 只针对设置 expire 过期的进行随机淘汰
- allkeys-random 所有的 key 随机淘汰
- volatile-ttl 淘汰 ttl 过期时间最小的 key
- noeviction 什么都不做,如果此时内存已满,系统无法写入
默认策略是 noeviction, 也就是不驱逐,此时如果写满,系统无法写入,建义设置为 LFU 相关的。**LRU 优先淘汰最近未被使用,无法应对冷数据,比如热 keys 短时间没有访问,就会被只使用一次的冷数据冲掉,无法反应真实的使用情况**
LFU 能避免上述情况,但是朴素 LFU 实现无法应对突发流量,无法驱逐历史热 keys,所以 redis LFU 实现类似于 W-TinyLFU, 其中 W 是 windows 的意思,即一定时间窗口后对频率进行减半,如果不减的话,cache 就成了对历史数据的统计,而不是缓存
上面还提到突发流量如果应对呢?答案是给新访问的 key 一个初始频率值,不至于由于初始值为 0 无法更新频率
LRU 实现
1 | int processCommand(redisClient *c) { |
在每次处理 client 命令时都会调用 freeMemoryIfNeeded 检查是否有必有驱逐某些 key, 当 redis 实际使用内存达到上限时开始淘汰。但是 redis 做的比较取巧,并没有对所有的 key 做 lru 队列,而是按照 maxmemory_samples 参数进行采样,系统默认是 5 个 key
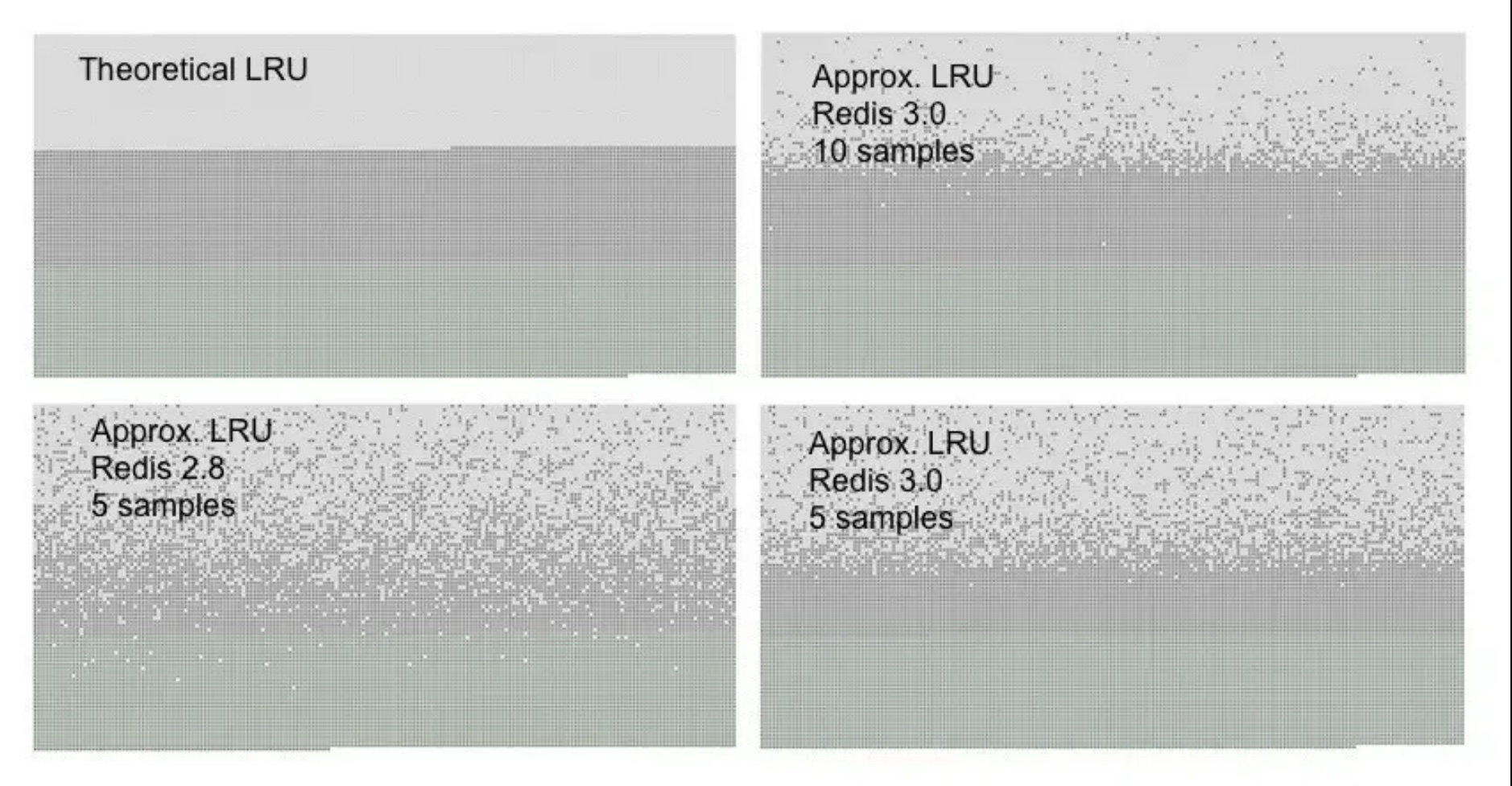
上面是很经典的一个图,当到达 10 个 key 时效果更接近理论上的 LRU 算法,但是 cpu 消耗会变高,所以系统默认值就够了。
LFU 实现
1 | robj *lookupKey(redisDb *db, robj *key, int flags) { |
当 lookupKey 访问某 key 时,会更新 LRU. 从 redis 4.0 开始逐渐引入了 LFU 算法,由于复用了 LRU 字段,所以只能使用 24 bits
1 | * We split the 24 bits into two fields: |
其中低 8 位 counter 用于计数频率,取值为从 0~255, 但是经过取对数的,所以可以表示很大的访问频率
高 16 位 ldt (Last Decrement Time)表示最后一次访问的 miniutes 时间戳, 用于衰减 counter 值,如果 counter 不衰减的话就变成了对历史 key 访问次数的统计了,而不是 LFU
1 | /* Update LFU when an object is accessed. |
LFUDecrAndReturn 将己有的 counter 计数衰减后返回,LFULogIncr 尝试对计数加一(有可能不加)后取对数,最后更新 val-lru
1 | unsigned long LFUTimeElapsed(unsigned long ldt) { |
注意由于 ldt 只用了 16位计数,最大值 65535,所以会出现回卷 rewind
LFU 获取己有计数
1 | * counter of the scanned objects if needed. */ |
num_periods 代表计算出来的待衰减计数,lfu_decay_time 代表衰减系数,默认值是 1,如果 lfu_decay_time 大于 1 衰减速率会变得很慢
最后返回的计数值为衰减之后的,也有可能是 0
LFU 计数更新并取对数
1 | /* Logarithmically increment a counter. The greater is the current counter value |
计数超过 255, 就不用算了,直接返回即可。LFU_INIT_VAL 是初始值,默认是 5
如果减去初始值后 baseval 小于 0 了,说明快过期了,就更倾向于递增 counter 值
1 | double p = 1.0/(baseval*server.lfu_log_factor+1); |
这个概率算法中 lfu_log_factor 是对数底,默认是 10, 当 counter 值较小时自增的概率较大,如果 counter 较大,倾向于不做任何操作
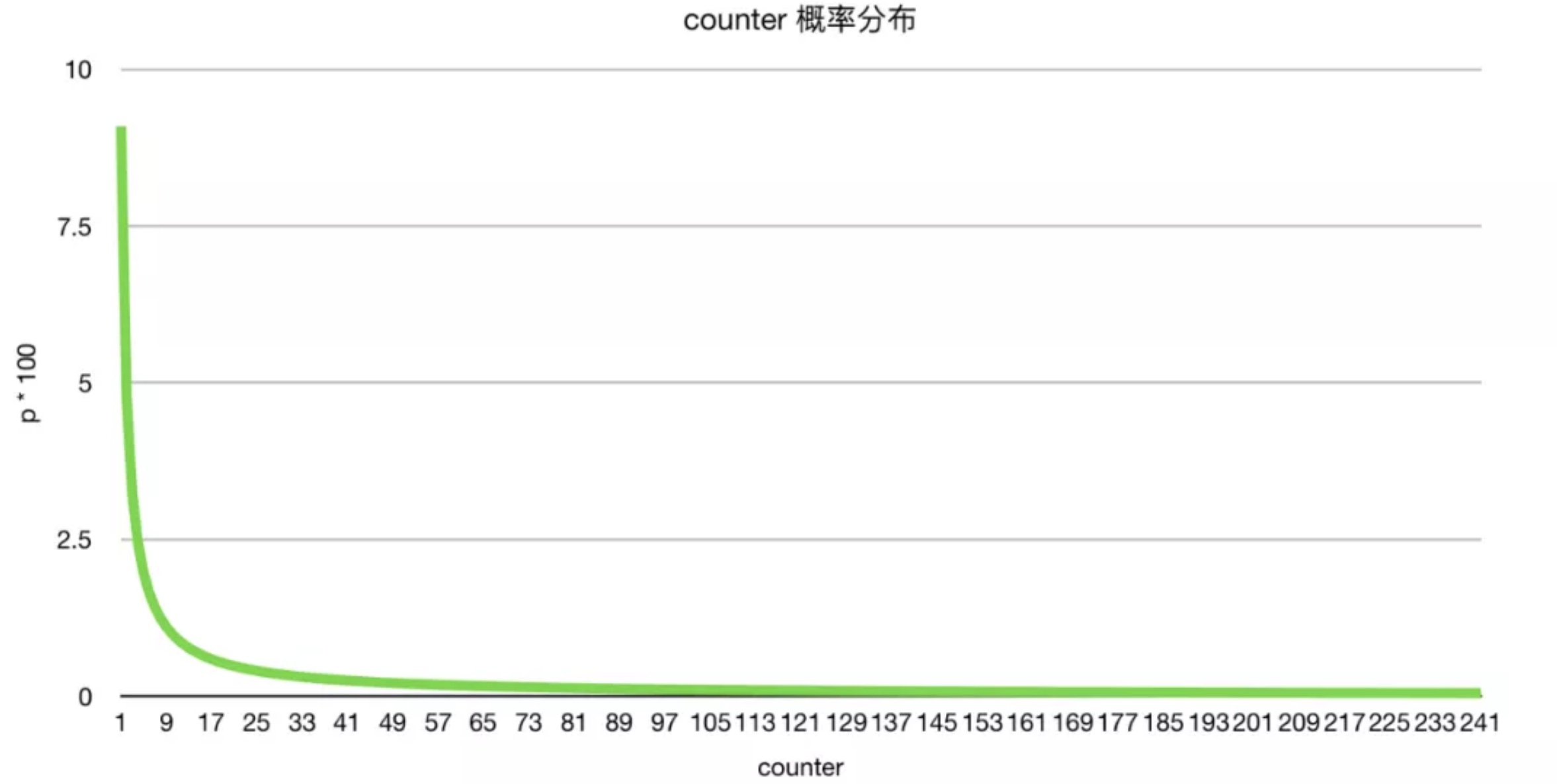
counter 值从 0~255 可以表示很大的访问频率,足够用了
1 | # +--------+------------+------------+------------+------------+------------+ |
基于这个特性,我们就可以用 redis-cli –hotkeys 命令,来查看系统中的最近一段时间的热 key, 非常实用。老版本中是没这个功能的,需要人工统计
1 | $ redis-cli --hotkeys |
谈谈缓存的指标
前面提到的是 redis LFU 实现,这是集中式的缓存,我们还有很多进程的本地缓存。如何评价一个缓存实现的好坏,有好多指标,细节更重要

- 吞吐量:常说的 QPS, 对标 bucket 实现的 hashmap 复杂度是 O(1), 缓存复杂度要高一些,还有锁竞争要处理,总之缓存库实现的效率要高
- 缓存命中率:光有吞吐量还不够,缓存命中率也非常关键,命中率越高说明引入缓存做用越大
- 高级特性:缓存指标统计,如何应对缓存击穿等等
小结
缓存是一个很大的 topic, 今天只分享冰山一角。写文章不容易,如果对大家有所帮助和启发,请大家帮忙点击在看,点赞,分享 三连
关于 淘汰算法 大家有什么看法,欢迎留言一起讨论,大牛多留言 ^_^
