你真的了解 Load Balance 嘛
在计算中,Load Balance 是指在一组资源(计算单元)上分配一组任务的过程,目的是使其整体处理更有效率。负载均衡可以优化响应时间,避免一些计算节点不均衡地超载,而其他计算节点则被闲置
同时,负载均衡, 反向代理, 网关 这些模块功能也比较相似,所以本文宽泛的将 LB 代指所有提供类似功能的开软软件以及设备
为什么需要 LB

能认识上图的人,都是 Old Gun 了。硬件负载均衡设备 F5 和 Netscaler
上一代互联网基础架构,必不可少的接入层设备,当时 lvs 刚起步,fullnat 还没有流行起来。所以需要硬件设备做接入层 LB
在赶集网的时候,Netscaler 有两台设备,一主一备,后来设备到期,公司因为成本问题,没有购买后续维修服务,硬是撑到了和 58 合并
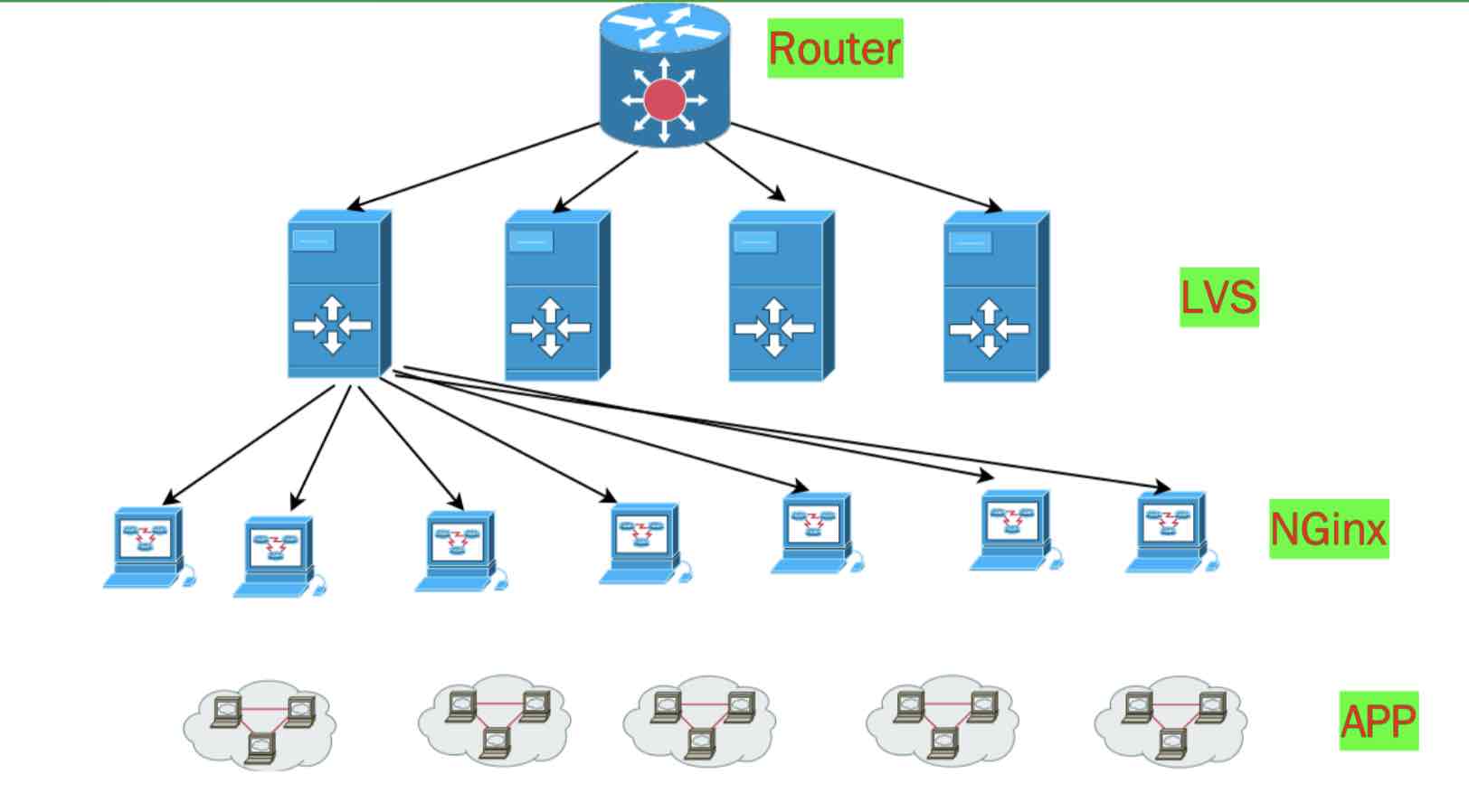
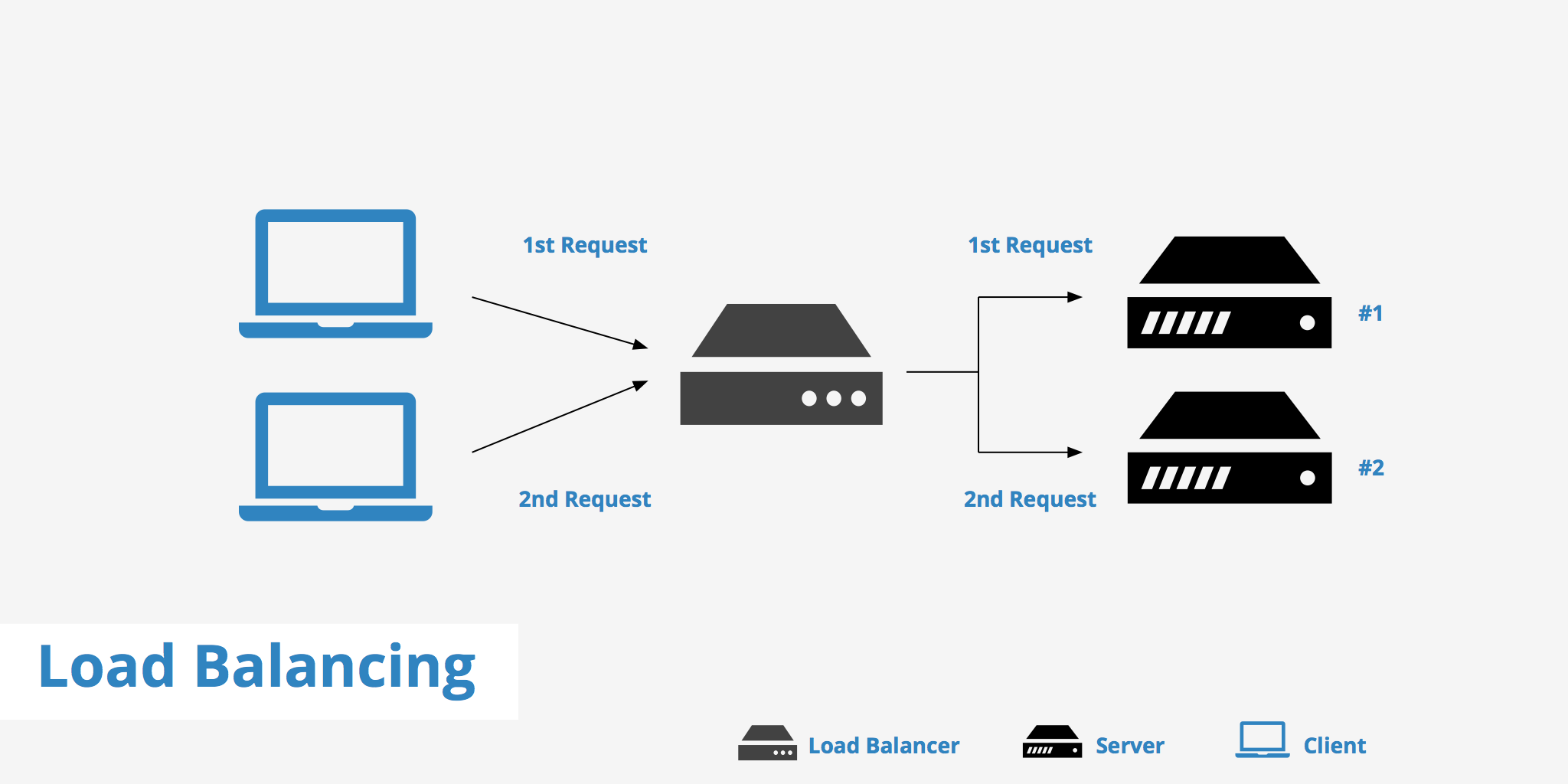
后来淘宝开源了 fullnat 模式的 lvs 代码,一般公司都是 lvs + nginx 实现接入层:对外 BGP IP, Lvs+OSPF 构建 tcp layer 4 接入层, nginx 负责 offload ssl 配置各种转发逻辑
宽泛来说,这里面 lvs, nginx 都是 Load Balance 软件,除了按照一定算法均衡 backend 设备的负载,LB 还要检测后端 Server 的存活状态,自动摘掉故障节点
基本常识
那么问题来了,如何构建 Load Balance 设备或是软件呢?本质还是理解 tcp/ip 模型及底层原理
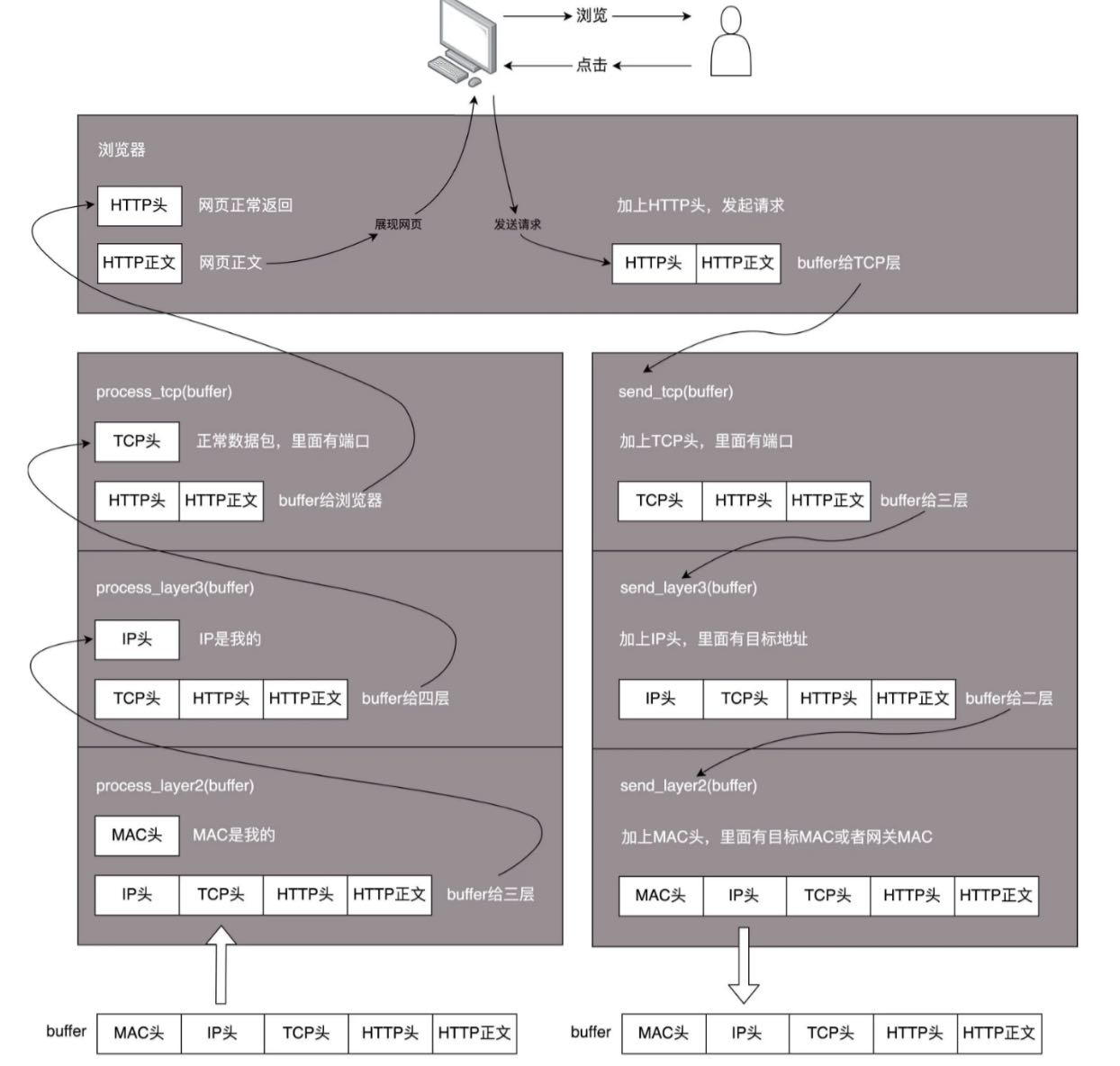
如上图所示,物理层,Mac 层,IP 层,TCP 层, HTTP/HTTPS 等七层。每层都是有不同的 header, 然后封装好 data 后传递给下一层,发送数据与接收数据逻辑相反
不同的 LB 及模式工作在不同模型,比如我们常见的 Nginx 常工作在七层,在用户态解析 http/https 协义然后转发请求
LVS 很多种模式,工作在二,三,四层都可以
Linux Virtual Server
Linux Virtual Server (lvs) 是 Linux 内核自带的负载均衡器,也是目前性能最好的软件负载均衡器之一。lvs 包括 ipvs 内核模块和 ipvsadm 用户空间命令行工具两部分
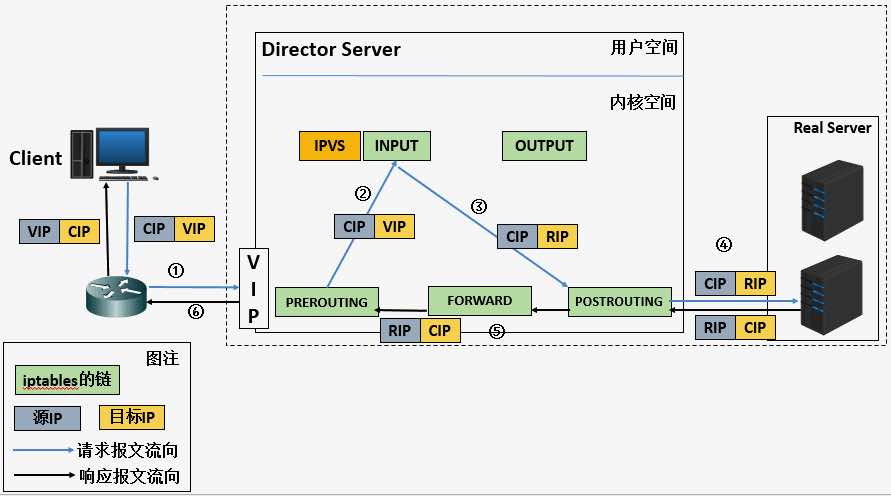
在 lvs 中,节点分为 Director Server 和 Real Server 两个角色,其中 Director Server 是负载均衡器所在节点,而 Real Server 则是后端服务节点
当用户的请求到达 Director Server 时,内核 netfilter 机制的 PREROUTING 链会将发往本地 IP 的包转发给 INPUT 链(也就是 ipvs 的工作链,在 INPUT 链上,ipvs 根据用户定义的规则对数据包进行处理(如修改目的 IP 和端口等),并把新的包发送到 POSTROUTING 链,进而再转发给 Real Server
阿里开源 LVS 很久了,但是最新的 fullnat 代码一直没放出,七牛使用的 lvs 内核版本过低,只能用 linux 2.7 kernel, 连硬件支持都很差了。所以后面会讲到 dpvs
Nat 是将修改数据包的目的 IP 和端口,将包转发给 RealServer (rs 不需要做任务设置), 此时 Director Server 即 LVS 是做为网关的,处于同一个局域网。包进来做 DNAT,出去做 SNAT
所有流量都经过 LVS, 很容易成为瓶颈。一般用于运维 OP 性质的多一些,服务正常业务流量有问题。
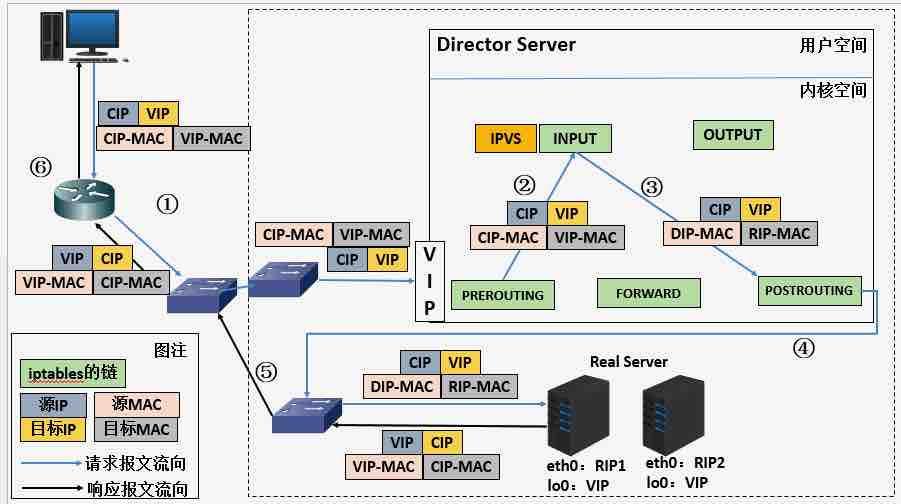
DR (Direct Route) 模式性能最好,工作在二层,通过修改数据包的 Mac 地址来实现转发,属于单臂 one-arm 模式,所以要求二层可达
进来的流量经过 LVS, 出去的直接返回给 client, 以前在赶集网时 MySQL 多用 DR 模式
这个模式需要修改 Real Server, 配置 arp_ignore 和 arp_announce 忽略对vip的ARP解析请求,同时 lo 添加对应的 VIP
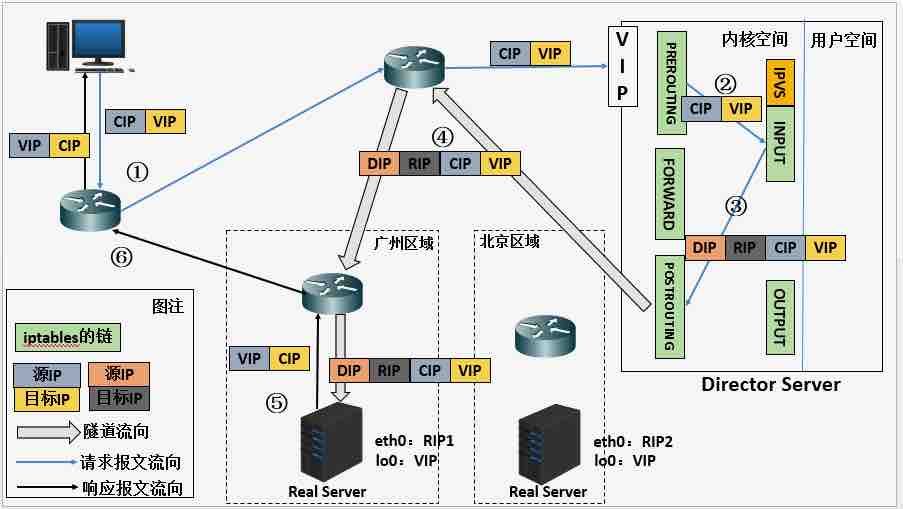
Tunnel 是典型的隧道模式
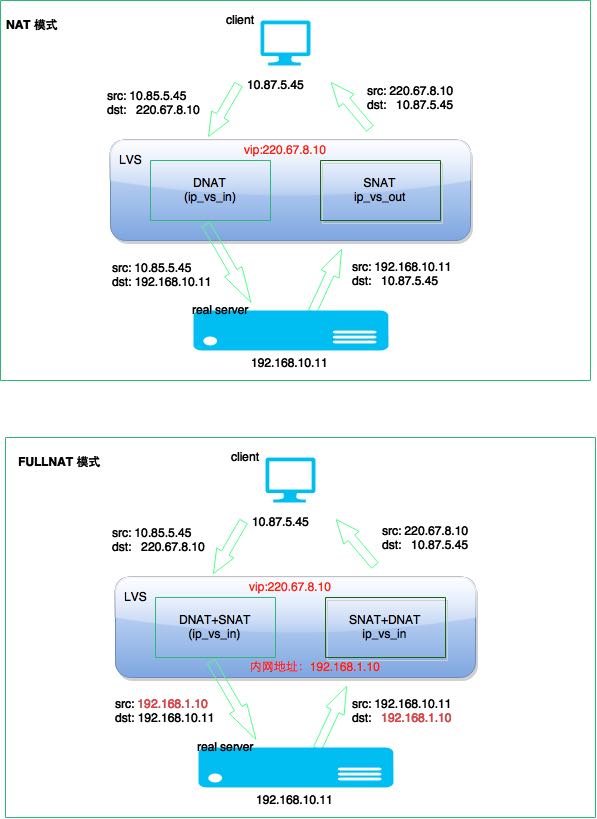
Fullnat 解决了 Nat 的不足,机器可以无限扩展,当然也要受限于单机 lvs 的网卡及 cpu 性能
DPDK + LVS = DPVS
IQIYI 前几年开源了 DPVS, 主流公司都有自己的 DPDK LB 轮子,你不造一个都不好意思说是大公司
另外,阿里开源的 fullnat 模块还停留在 linux 2.6.32 kernel, 很多现代机器支持不好,而且 2021 年了,linux 主流内核都是 4.0 及以上
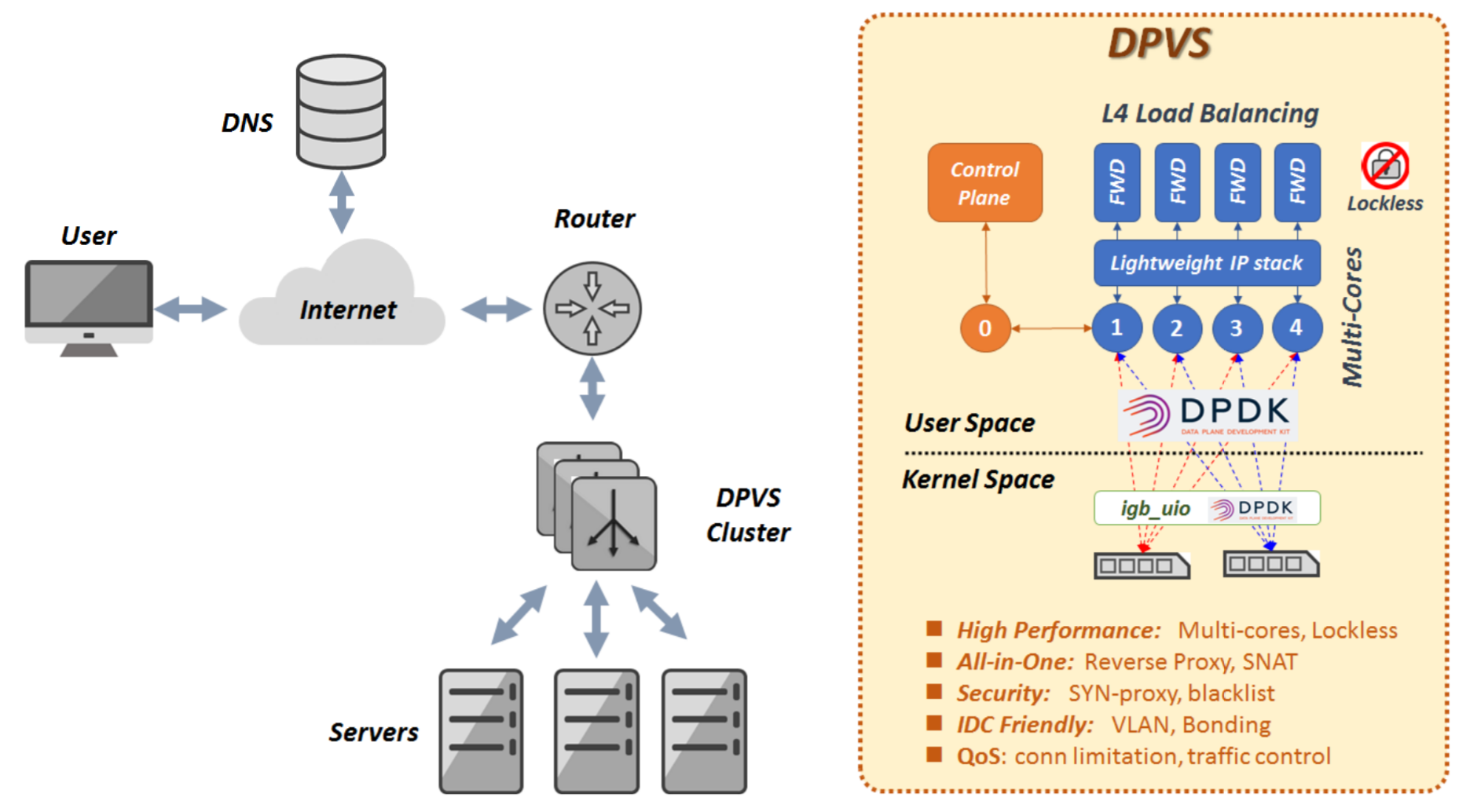
主要优化就是由 DPDK bypass 内核,完全用户态接管网卡,同时重写 tcp/ip 协义栈代码
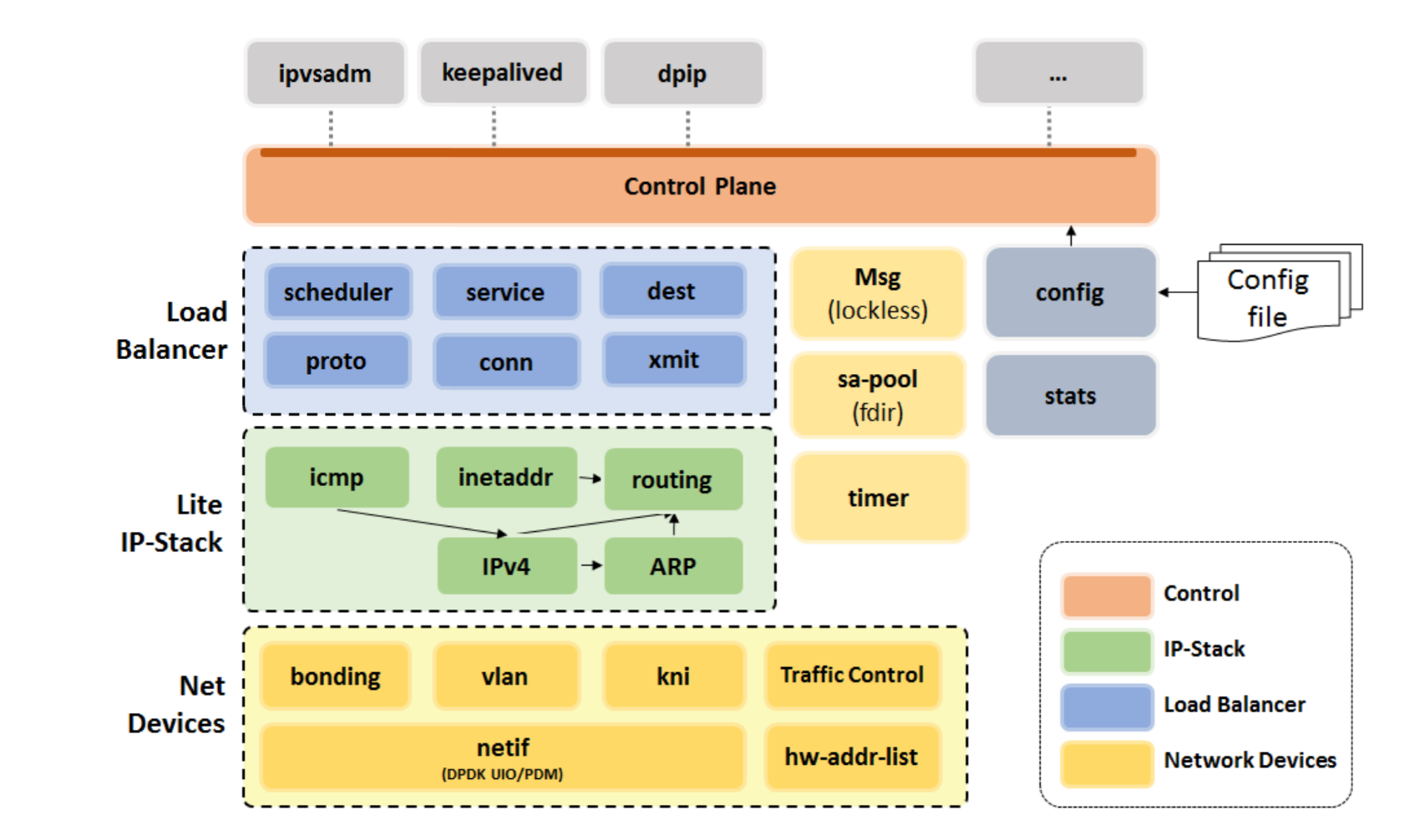
上面是 dpvs 的整体架构,里面细节超多,感兴趣可以网上搜我的文章,以前写过一系列
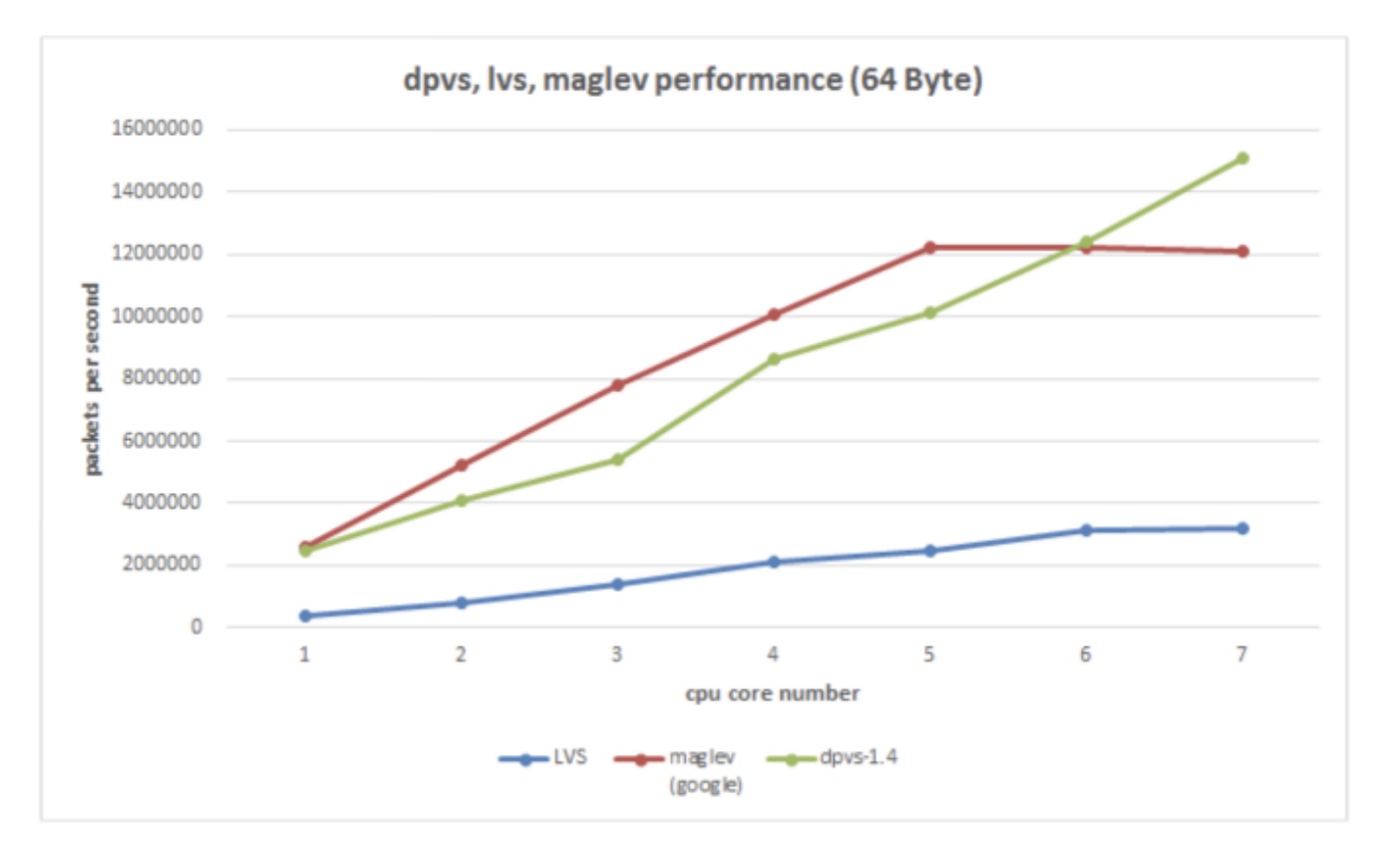
性能 Benchmark 据说可以达到线速,公司用的话还得调优。开源产品宣传的很好,实际测起来数据可能不是那么回事,需要有专人调优
调度算法
- Round-robin (ip_vs_rr.c)
- Weighted round-robin (ip_vs_wrr.c)
- Least-connection (ip_vs_lc.c)Weighted least-connection (ip_vs_wlc.c)
- Locality-based least-connection (ip_vs_lblc.c)
- Locality-based least-connection with replication (ip_vs_lblcr.c)
- Destination hashing (ip_vs_dh.c)
- Source hashing (ip_vs_sh.c)
- Shortest expected delay (ip_vs_sed.c)
- Never queue (ip_vs_nq.c)
- Maglev hashing (ip_vs_mh.c)
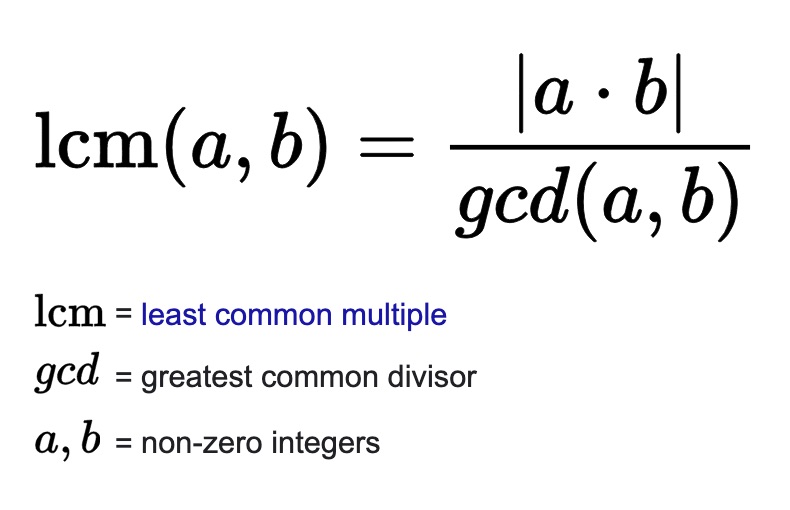
上面是主流 LB 设备的调度算法,面试八股文必备,一般 RR 简单的轮询就够了。复杂一些的需要加个权,一般都是辗转相除实现的 GCD 最大公约数
这就够了嘛?其实不够的,比如我们线上遇到过预热的问题,服务流量特别大,新起来的机器 RR 过来的话瞬间 QPS 超高,影响服务性能,表现为 GC 特别频繁,同时请求的 latency 非常高
怎么解决呢?参考 Nginx 的 Smooth Weighted Round-Robin (SWRR) 平滑移动加权算法
云厂商的 LB
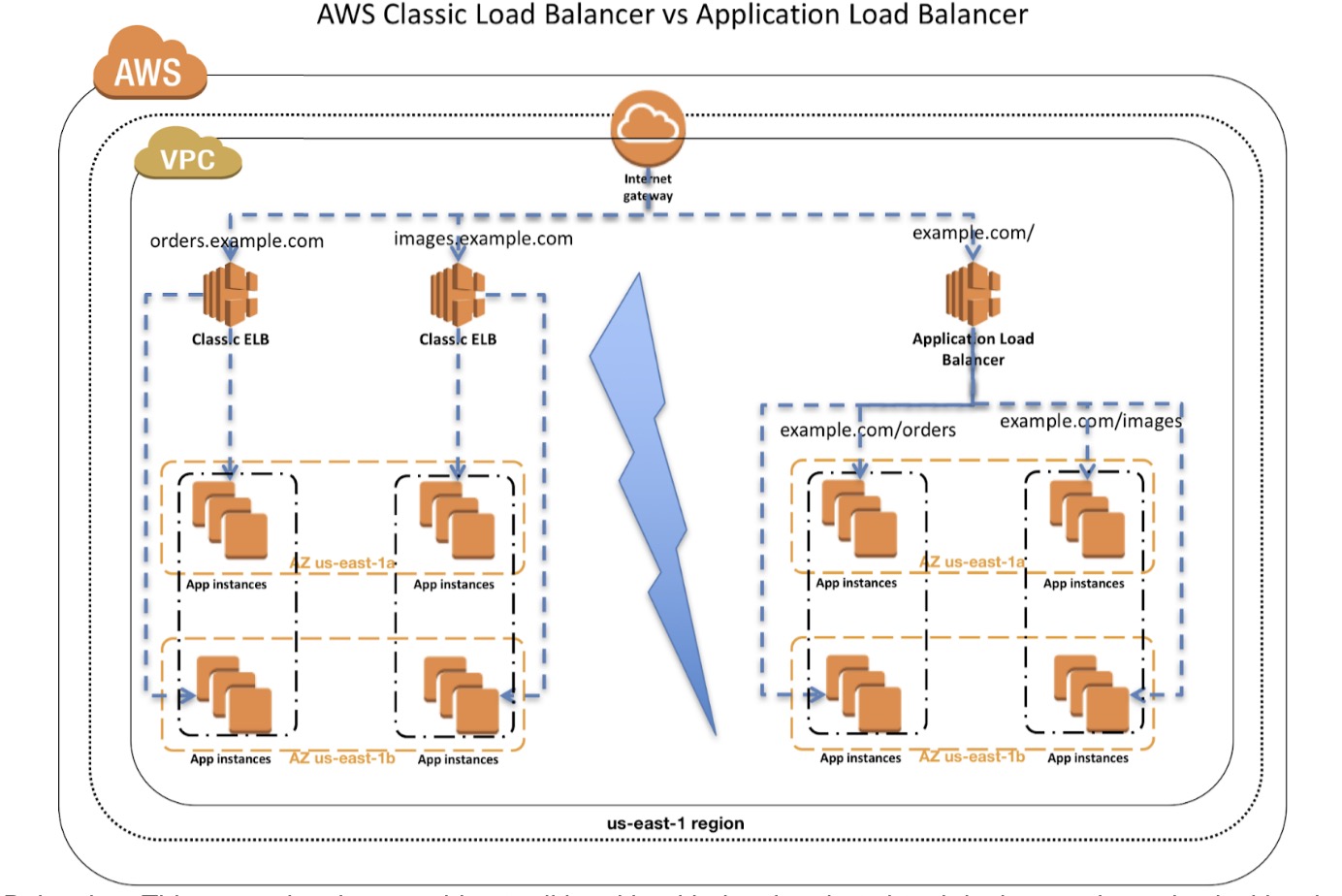
暂时只看 AWS Cloud, 一般我们都用 elb 做入口,涉及到 elb, alb, clb, nlb 概念巨多
大家可以参考官网看下区别,无外乎是否支持 layer 4、layer 7, 是否支持按 path 路由,还有一些高级功能等等的区别
具体实现,因为是黑盒,可能 c/c++ 自己写,也可能是 nginx 魔改,谁知道呢
K8S 的 LB
K8S 里面主要是三类:Service 四层,Ingress 七层,以及所谓的 Service Mesh 模式
Service 允许指定你所需要的 Service 类型,默认是 ClusterIP, 主要类型有:
ClusterIP:通过集群的内部 IP 暴露服务,选择该值时服务只能够在集群内部访问。 这也是默认的 ServiceType。
NodePort:通过每个节点上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到自动创建的 ClusterIP 服务。通过请求 <节点 IP>:<节点端口>,你可以从集群的外部访问一个 NodePort 服务。
LoadBalancer:使用云提供商的负载均衡器向外部暴露服务。外部负载均衡器可以将流量路由到自动创建的 NodePort 服务和 ClusterIP 服务上。
ExternalName:通过返回 CNAME 和对应值,可以将服务映射到 externalName 字段的内容(例如,foo.bar.example.com), 无需创建任何类型代理。
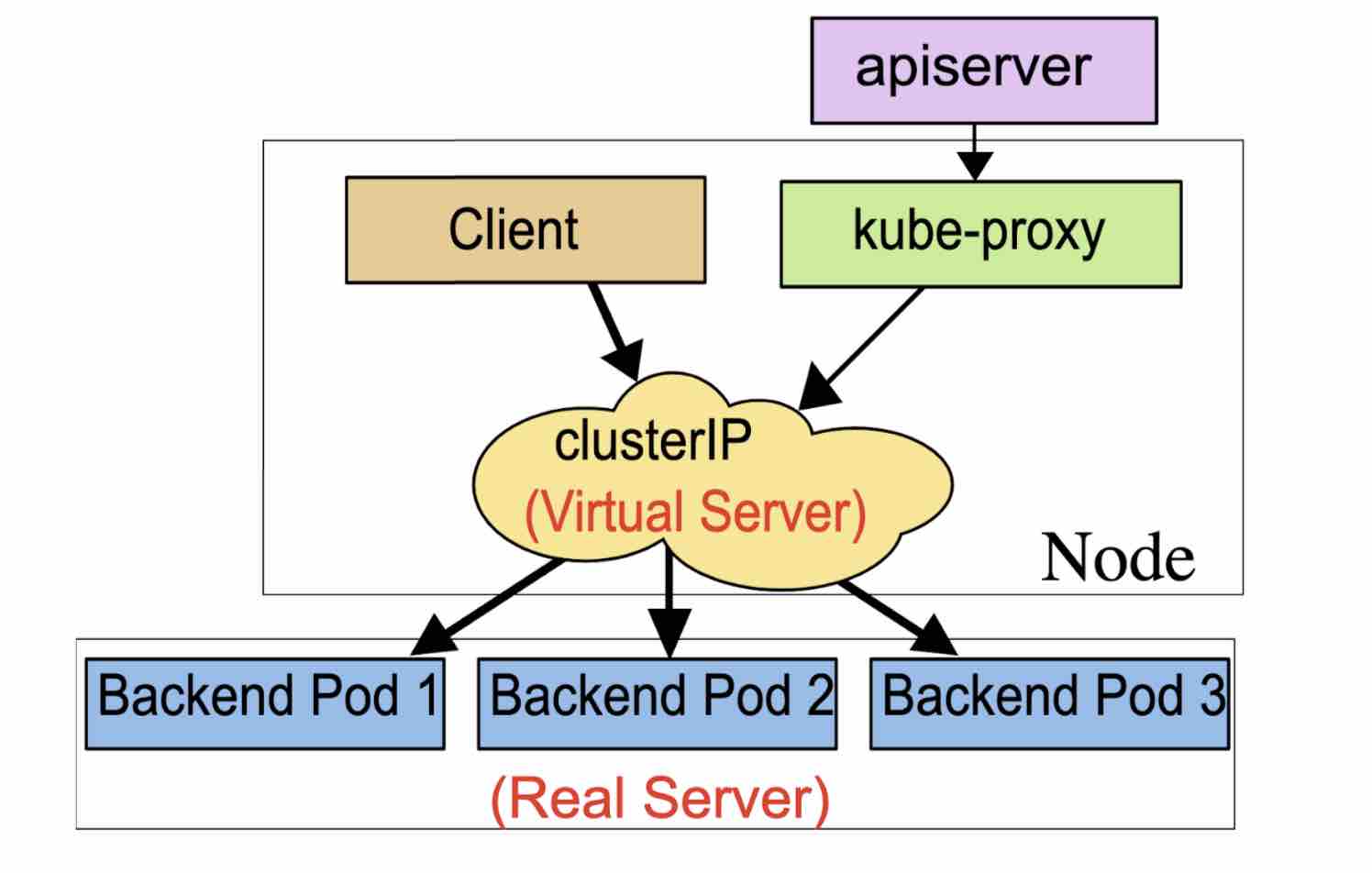
除了类型主要用三种工作模式:userspace proxy, iptables model, ipvs model. 现在性能最好默认的就是 ipvs 模式,如果机器不支持会 fallback 到 iptables
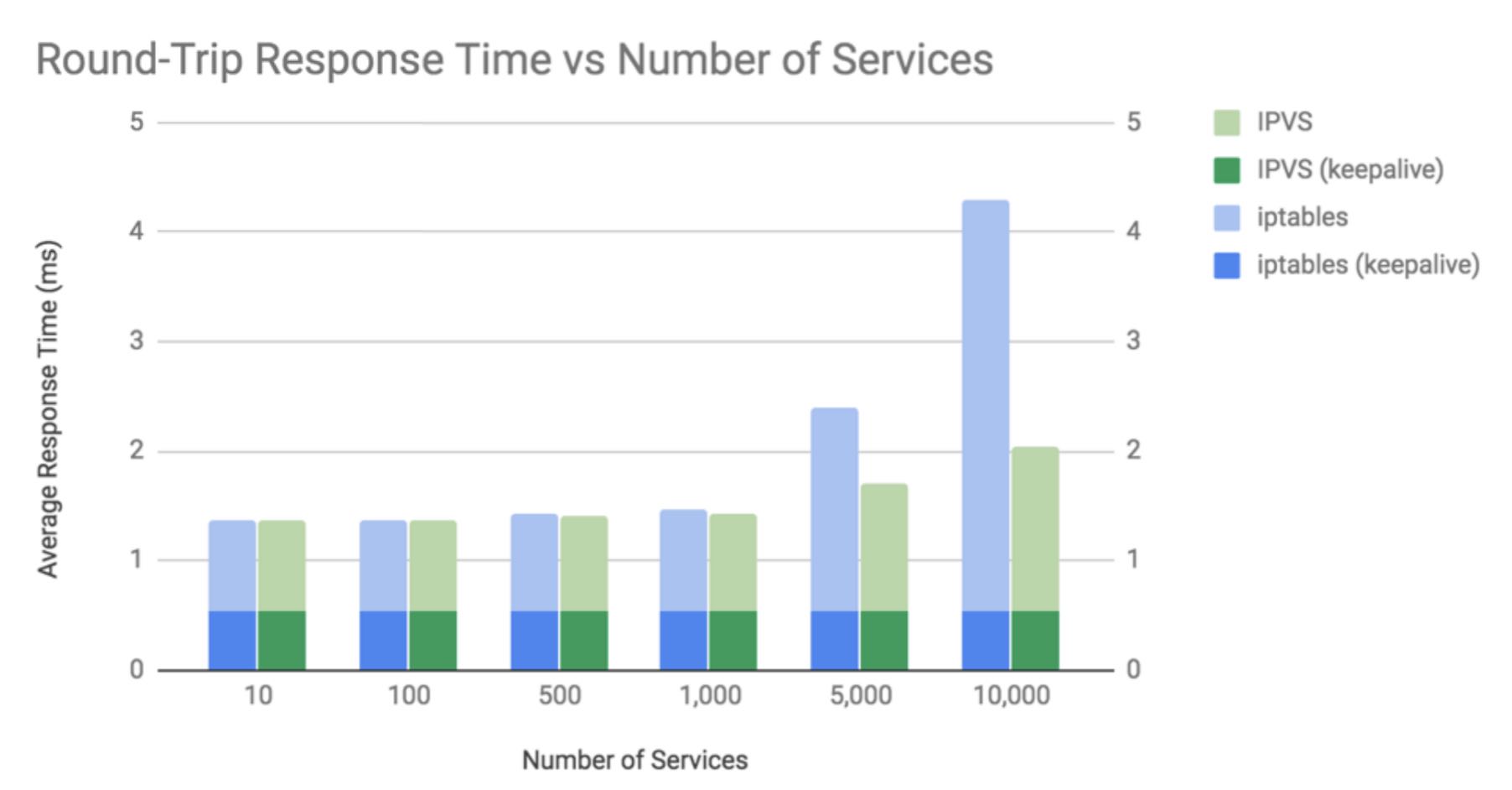
网上有性能对比,差距还是蛮明显的。
Service 工作在四层,有些需求是按照 path 把请求转发到不同服务,这时就需要用到 Ingress
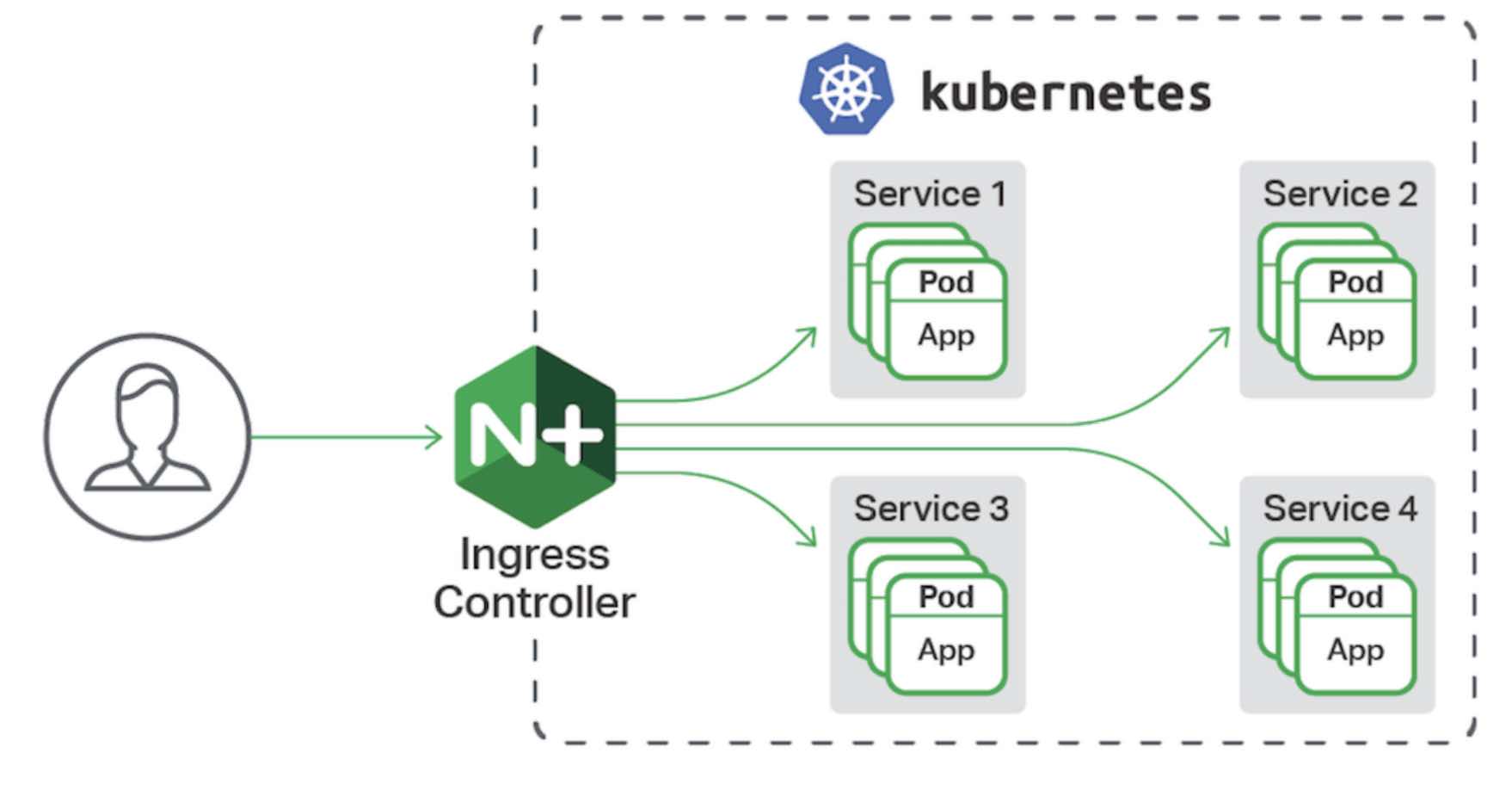
上图的 Ingress 由 nginx 实现,感兴趣的可以参考官网

对于流行的 Service Mesh, 每个 POD 都有 sidecar 容器来劫持流量,好处是业务无需配置服务发现,熔断,限流等等,这些都由 SM 的控制面来配,缺点是中间引入过多的 proxy, 服务可观测性是个挑战
小结
今天的分享就这些,写文章不容易,如果对大家有所帮助和启发,请大家帮忙点击再看,点赞,分享 三连
关于 Load Balance 大家有什么看法,欢迎留言一起讨论,大牛多留言 ^_^
