~# strace -ce clock_gettime go run time_demo.go Time taken: 1.983µs Time taken: 1.507µs Time taken: 2.247µs Time taken: 2.993µs Time taken: 2.703µs Time taken: 1.927µs Time taken: 2.091µs Time taken: 2.16µs Time taken: 2.085µs Time taken: 2.234µs % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 100.00 0.001342 13 105 clock_gettime ------ ----------- ----------- --------- --------- ---------------- 100.00 0.001342 105 total
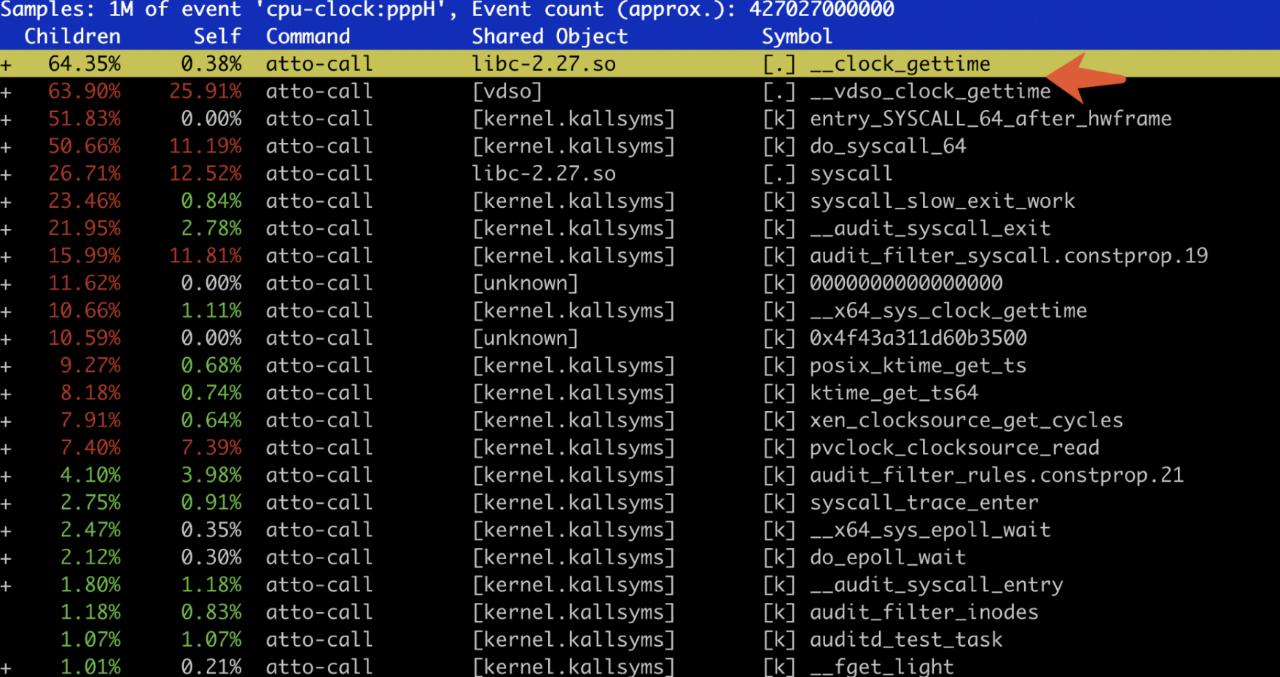
上面是有问题的机器结果,可以发现大量的系统调用 clock_gettime 产生。
1 2 3 4 5 6 7 8 9 10 11
~# strace -ce clock_gettime go run time_demo.go Time taken: 138ns Time taken: 94ns Time taken: 73ns Time taken: 88ns Time taken: 87ns Time taken: 83ns Time taken: 93ns Time taken: 78ns Time taken: 93ns Time taken: 99ns
time 只暴露了函数的定义,实现是由底层不同平台的汇编实现,暂时只关注 amd64, 来看下汇编代码
1 2 3 4 5 6 7 8 9 10 11
// src/runtime/sys_linux_amd64.s // func walltime1() (sec int64, nsec int32) // non-zero frame-size means bp is saved and restored TEXT runtime·walltime1(SB),NOSPLIT,$8-12 ...... noswitch: SUBQ $16, SP // Space for results ANDQ $~15, SP // Align for C code
x86-64 functions The table below lists the symbols exported by the vDSO. All of these symbols are also available without the "__vdso_" prefix, but you should ignore those and stick to the names below. symbol version ───────────────────────────────── __vdso_clock_gettime LINUX_2.6 __vdso_getcpu LINUX_2.6 __vdso_gettimeofday LINUX_2.6 __vdso_time LINUX_2.6
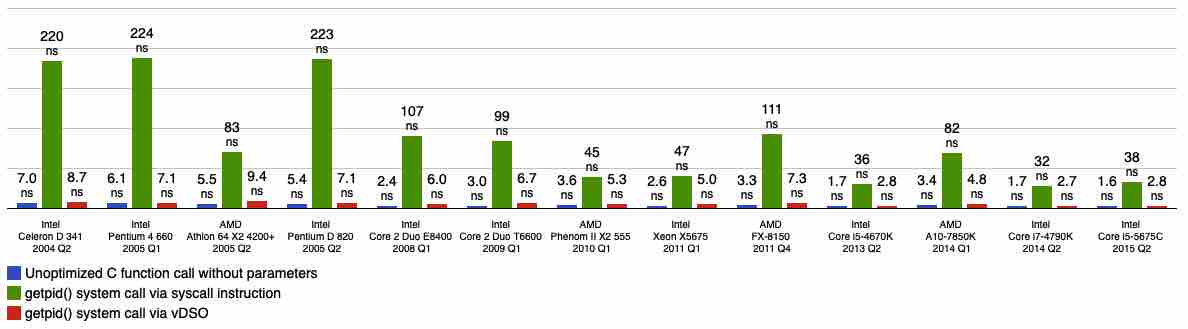
上面就是 x86 支持 vdso 的函数,一共 4 个?不可能这么少吧?来看一下线上真实情况的
1 2 3 4
~# uname -a Linux 5.4.0-1041-aws #43~18.04.1-Ubuntu SMP Sat Mar 20 15:47:52 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux ~# cat /proc/self/maps | grep -i vdso 7fff2edff000-7fff2ee00000 r-xp 00000000 00:00 0 [vdso]
/* * Read without the seqlock held by clock_getres(). * Note: No need to have a second copy. */ WRITE_ONCE(vdata[CS_HRES_COARSE].hrtimer_res, hrtimer_resolution);
/* * If the current clocksource is not VDSO capable, then spare the * update of the high reolution parts. */ if (clock_mode != VDSO_CLOCKMODE_NONE) update_vdso_data(vdata, tk);
/* Check for negative values or invalid clocks */ if (unlikely((u32) clock >= MAX_CLOCKS)) return-1;
/* * Convert the clockid to a bitmask and use it to check which * clocks are handled in the VDSO directly. */ msk = 1U << clock; if (likely(msk & VDSO_HRES)) { return do_hres(&vd[CS_HRES_COARSE], clock, ts); } elseif (msk & VDSO_COARSE) { do_coarse(&vd[CS_HRES_COARSE], clock, ts); return0; } elseif (msk & VDSO_RAW) { return do_hres(&vd[CS_RAW], clock, ts); } return-1; }
do { seq = vdso_read_begin(vd); cycles = __arch_get_hw_counter(vd->clock_mode); ns = vdso_ts->nsec; last = vd->cycle_last; if (unlikely((s64)cycles < 0)) return-1;
ns += vdso_calc_delta(cycles, last, vd->mask, vd->mult); ns >>= vd->shift; sec = vdso_ts->sec; } while (unlikely(vdso_read_retry(vd, seq)));
/* * Do this outside the loop: a race inside the loop could result * in __iter_div_u64_rem() being extremely slow. */ ts->tv_sec = sec + __iter_div_u64_rem(ns, NSEC_PER_SEC, &ns); ts->tv_nsec = ns;
staticinline u64 __arch_get_hw_counter(s32 clock_mode) { if (clock_mode == VCLOCK_TSC) return (u64)rdtsc_ordered(); /* * For any memory-mapped vclock type, we need to make sure that gcc * doesn't cleverly hoist a load before the mode check. Otherwise we * might end up touching the memory-mapped page even if the vclock in * question isn't enabled, which will segfault. Hence the barriers. */ #ifdef CONFIG_PARAVIRT_CLOCK if (clock_mode == VCLOCK_PVCLOCK) { barrier(); return vread_pvclock(); } #endif #ifdef CONFIG_HYPERV_TIMER if (clock_mode == VCLOCK_HVCLOCK) { barrier(); return vread_hvclock(); } #endif return U64_MAX; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14
static u64 vread_pvclock(void) { ...... do { version = pvclock_read_begin(pvti);
if (unlikely(!(pvti->flags & PVCLOCK_TSC_STABLE_BIT))) return U64_MAX;
ret = __pvclock_read_cycles(pvti, rdtsc_ordered()); } while (pvclock_read_retry(pvti, version));
/* * * Assuming a stable TSC across physical CPUS, and a stable TSC * across virtual CPUs, the following condition is possible. * Each numbered line represents an event visible to both * CPUs at the next numbered event. */ staticvoidpvclock_update_vm_gtod_copy(struct kvm *kvm) { ...... ka->use_master_clock = host_tsc_clocksource && vcpus_matched && !ka->backwards_tsc_observed && !ka->boot_vcpu_runs_old_kvmclock; ...... }