Head Of Line Blocking 困扰两个月的线上问题
我们最近遇到一个问题,内部某个服务是有状态的,有些请求需要在内部做转发,但是请求偶尔发生超时,随机超时,并且没有任何规律,和 QPS 无关,一般 2s 内都恢复了。
经过两个月排查,不断的 narrow down, 最终排除业务代码问题,定位 root cause 是 tcp restranmit 引起的 HOL(head of line) blocking, 己经给 aws 提了 ticket, 至于重传的原因还在与 aws 确认中。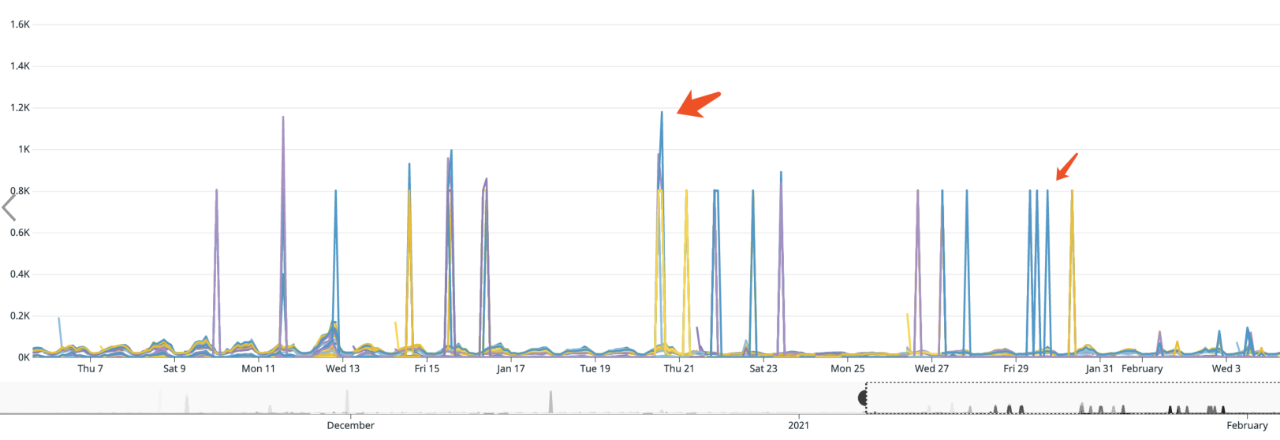
排查过程
我司代码由 grab-kit 框架生成,去年 gopher china 2020 有同事做了分享,感兴趣的可以去看 slide.
技术栈统一用 grpc 协义,服务发现使用 etcd, 同时 client 与 server 端也定义了大量的 Middleware, 比如 circuit breaker, logging, retry, chaos, statsd 等等,非常方便。
但也因为是框架生成的代码,比较难排查,我们加了好多额外踪追代码,排除是业务代码问题。
最终 narrow down 到 grpc 与网络上,通过 tcpdump 抓包石锤 RC 是 tcp restranmit
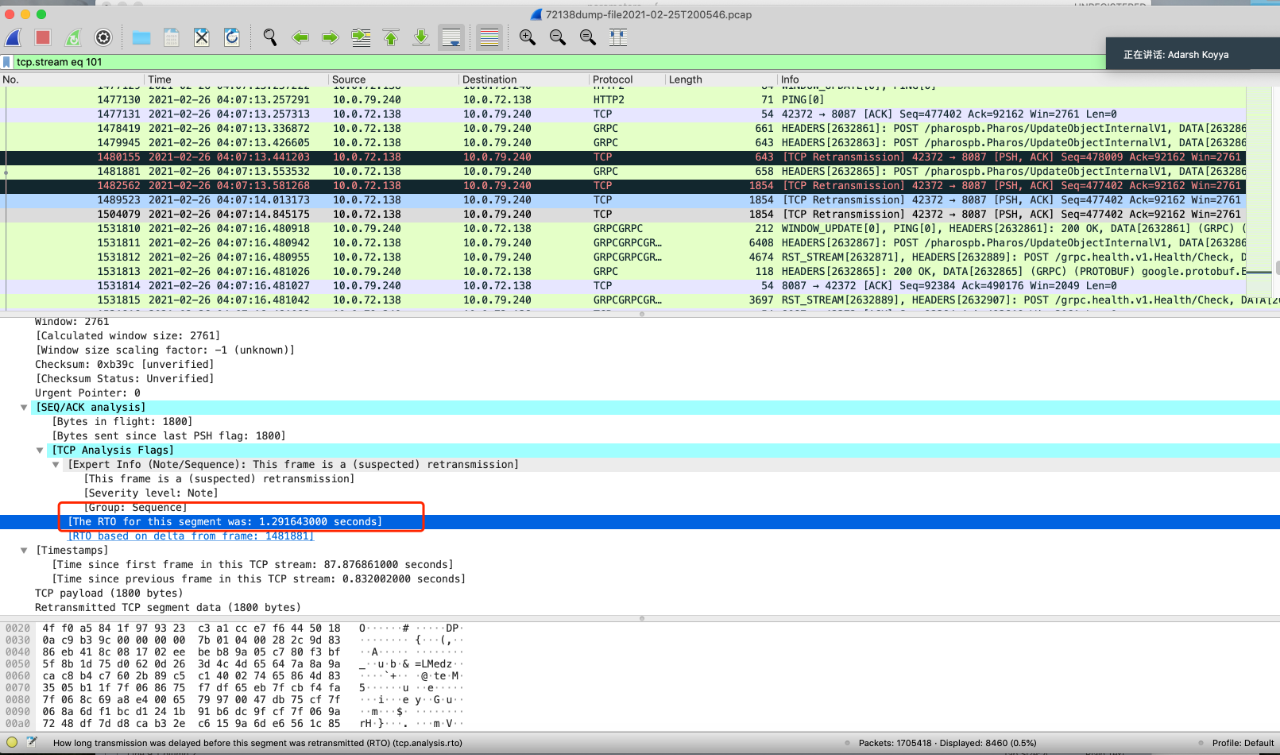
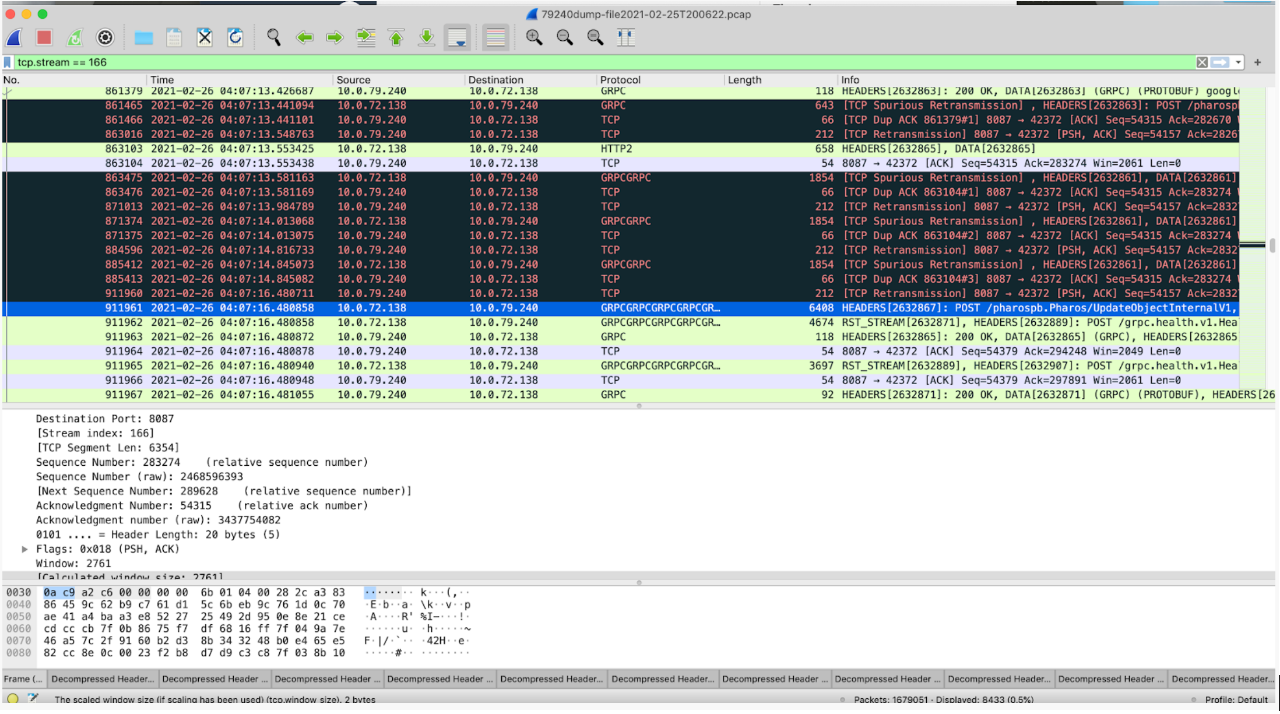
上图分别是 client, server 抓包的分析,可以清晰的看到 tcp 大量的重传,那么为什么重传会引起很多请求超时呢?
HTTP
当 http2 周边生态稳定后,老的 http1 一定会退出历史舞台的,本质就是 http1 无法充分发挥 tcp 的性能。
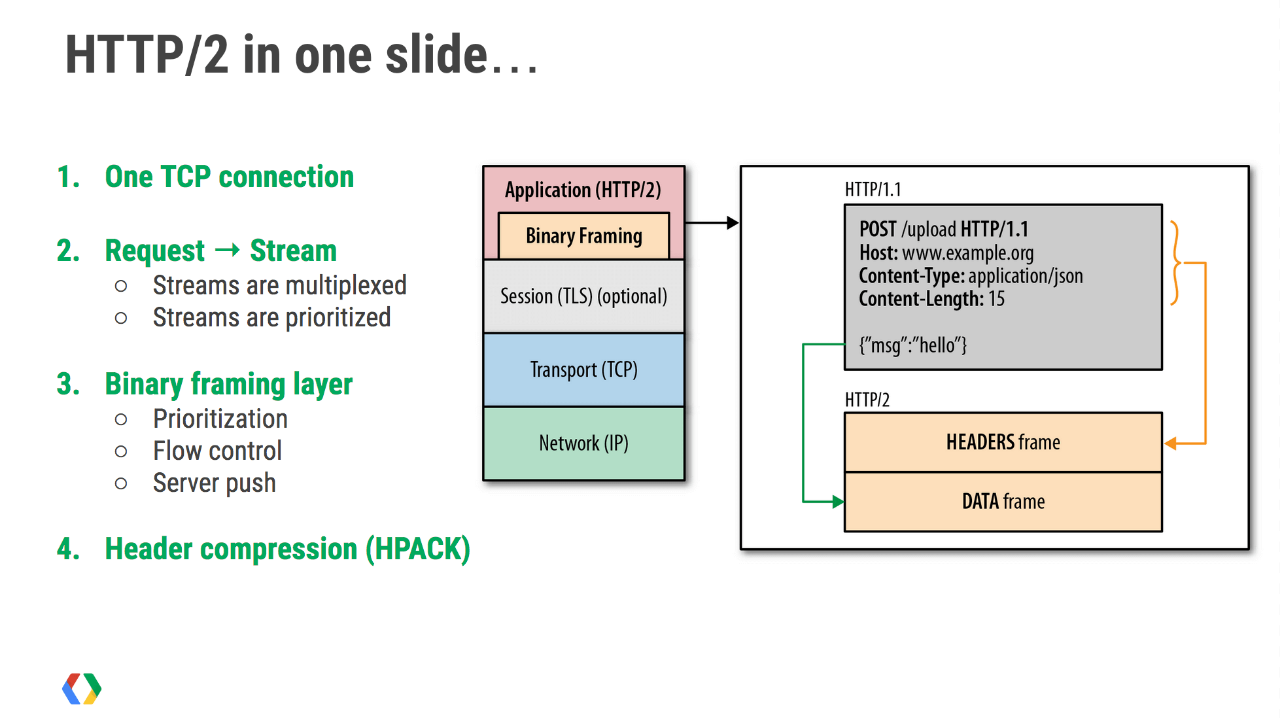
http2 是一个彻彻底底的二进制协议,头信息和数据包体都是二进制的,统称为“帧”。对比 http1, 头信息是文本编码(ASCII编码),数据包体可以是二进制也可以是文本。使用二进制作为协议实现方式的好处,更加灵活。在 http2 中定义了 10 种不同类型的帧。
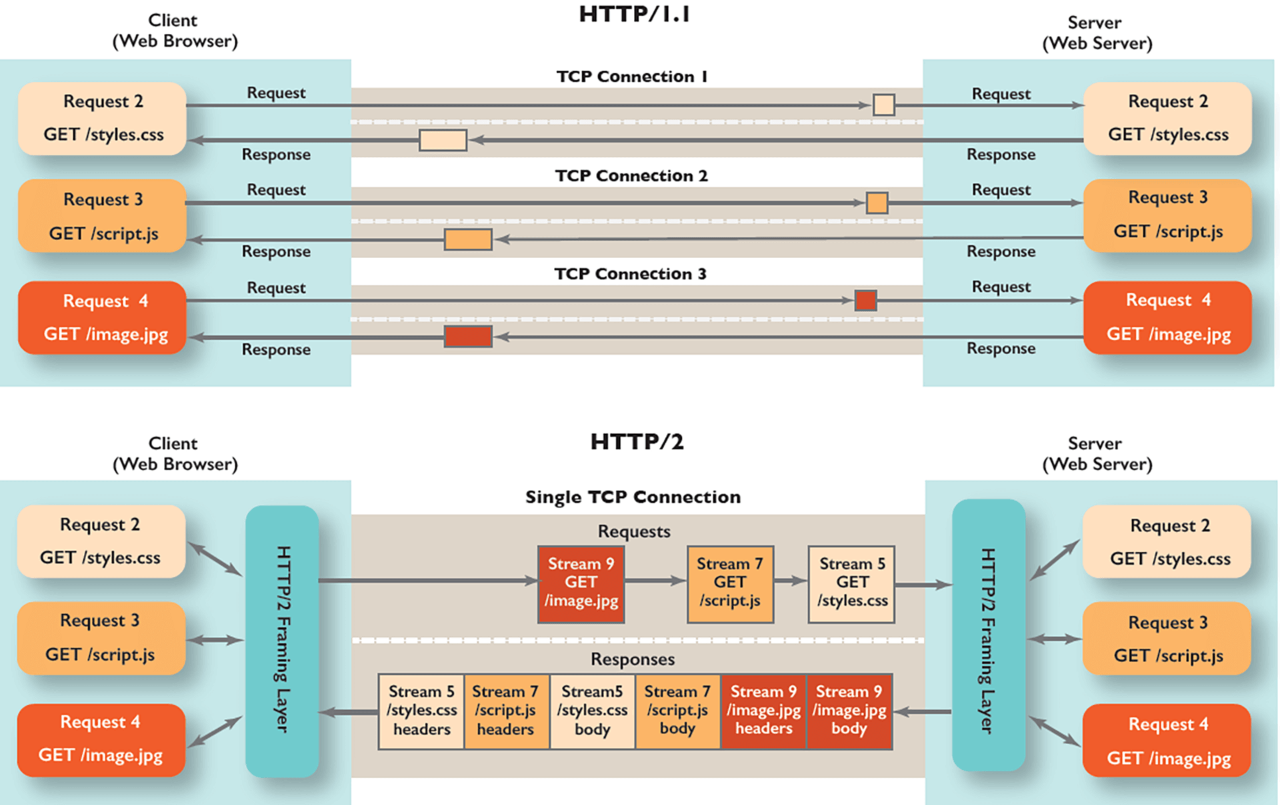
如上图所示,由于 http2 的数据包是乱序发送的,因此在同一个连接里会收到不同请求的 response。不同的数据包携带了不同的标记,用来标识它属于哪个 response。
http2 把每个 request 和 response 的数据包称为一个数据流(stream)。每个数据流都有自己全局唯一的编号。每个数据包在传输过程中都需要标记它属于哪个数据流 ID。规定,客户端发出的数据流,ID 一律为奇数,服务器发出的,ID 为偶数。
也就是说,对于 http1, 我们要使用连接池,或是纯粹短连接,但是对于 http2 由于多路复用的存在,理论上一个 tcp 长连接就可以,我司线上一般都是 4 个。
HOL blocking
那么 http2 就没有问题了嘛?不是的。HOL blocking 队首阻塞原以为只活在教科书里,没想到这次遇到了。
http1 协义可以使用 pipeline 的方式复用 tcp 连接,但是如果一个请求慢了,那么后续其它的请求只能等待,这个就算是 OSI 协义上七层的 HOL blocking
而对于 http2 来说,虽然七层由虚拟 stream 做到了多路复用,但是仍然存在四层 tcp 的阻塞,如果一个 packet 因为某种原因重传,那么同一个 tcp 连接上后面的 requests 也会等待,直到超时重传成功。这也就是为什么 http2 的连接理论上一个就够了,但是实践中还要创建多个 tcp 连接。

上图就是 http2 模拟 HOL 的动图,非常形像。那么如果解决这个问题呢?那就是 http3 也就是 quick based on UDP

动图很形像了,某一个虚拟 stream 的包丢失重传了,并不影响其它 stream 的。本质还是由于 UDP 是无状态的,非面向连接
TODO
后续就是与 aws 一起排查重传的原因了,怀疑两个方向: ec2 宿主机网络问题,os AMI 问题。
前都只能由 aws 定位了,os AMI 问题会比较麻烦,涉及 kernel tcp stack 源码,暂时没有其它思路了。希望能尽快 fix 这个问题。
小结
这次分享就这些,以后面还会分享更多的内容,如果感兴趣,可以关注并点击左下角的分享转发哦(:
