美图 kv 存储 titan

市面上开源 kv 轮子一大堆,架构上都是 rocksdb 做单机引擎,上层封装 proxy, 对外支持 redis 协议,或者根据具体业务逻辑定制数据类型,有面向表格 table 的,有做成列式存储的
国内公司大部分都有自己的轮子,开发完一代目拿到 KPI 走人,二代目继续填坑,三四代沦为边缘。即使开源也很难有持续的动力去维护,比如本文要分享的 美图 titan,很多优化的 proposals 都没实现,但是做为学习项目值得研究,万一哪天二次开发呢
整体架构
Titan 代码 1.7W 行,纯 go 语言实现。server 层只负责处理用户请求,将 redis 数据结构映射成 rocskdb key/value, 底层使用 tikv 集群
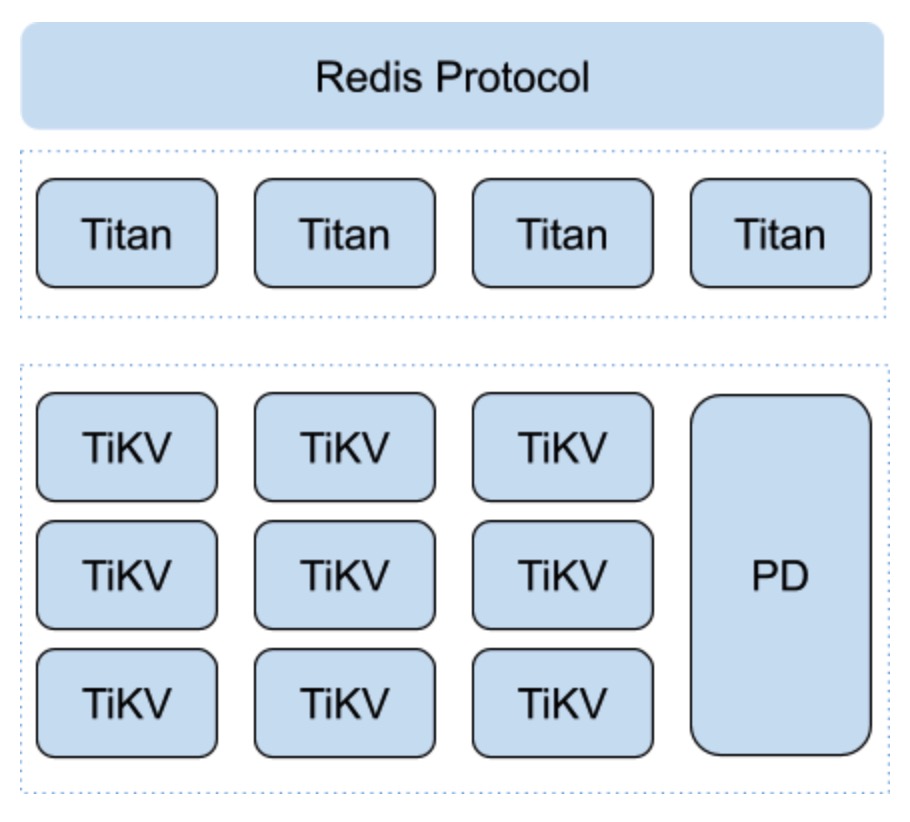
站在巨人的肩膀上,titan 无需考滤数据 rebalance, 不关心数据存储副本同步,这也是为什么代码量如此少
压测 数据只有 2018 年的,性能一般,latency 也没区分 99 和 95 分位。如果基于最新版本的 tikv 集群测试效果可能更好
数据类型实现
目前数据结构只实现了 string, set, zset, hash, list, 有些也只是部分支持,只能说够用
持久化的 kv 轮子,难点就是如何把 redis 数据结构与 rocksdb key/value 做映射。原来单进程天然实现的原子性很难实现,维护一种数据涉及多个 key, 如果分布在多个 instance 进程又涉及了分布式事务,吞吐自然降低很多
比然我们常用 lua 脚本自定义一些业务逻辑,将涉及的多个 key 用 hash tag 处理下,变成同一个 redis slot, 但这在 titan 里是做不到的
性能问题,比如 HLEN 操作,本来 redis O(1) 操作,如果在 titan 的 hash metakey 中维护 len 记录,那么高并发写删 hash 时就会有大量冲突。再比如 zset 数据结构,zrange, zrangebyscore, zrangebylex 需要将 member, score 分别编码存储,用空间换时间
String
String 类型只有两种 key: MetaKey, ExpireKey

MetaKey 中 namespace 用于实现多租户隔离,但也只是逻辑上的,毕竟资源仍然是共用的,dbid 类似 redis db0, db1 …
ExpireKey 用于主动过期数据,后台任务定期扫。每个类型都有,后面省略不表
MetaValue 前 42 字节为属性信息,后面才是真正的用户 value. 时间字段表示创建,更新,过期 timestamp, 被动过期时会检查 ExpireAt. uuid 用于唯一标识 key, titan 主动 GC 会用到
Type 表示数据类型
1 | const ( |
Encoding 表示具体的编码类型
1 | const ( |
为了兼容,定义与 redis 一致
Set

MetaKey 与 String 类型一样,MetaValue 一共 50 字节,前 42 字节一样,后 8 字节维护集合 Set 成员数量信息。也就是说后续的 SCARD 是 O(1),但同时删除增加都要修改 MetaValue
DataKey 编码了 Set 唯一 uuid 与成员 member 信息,由于集合只需要成员 member, 所以 DatValue 是 []byte{0}
Zset

与集合一样,zset MetaKey/MetaValue 内容一样
DataKey 内容基本一样,DataValue 是 score 值,同时也维护了 score -> member 映射的 ScoreKey, 用于空间换时间方便 zrangebyscore 查询
Hash
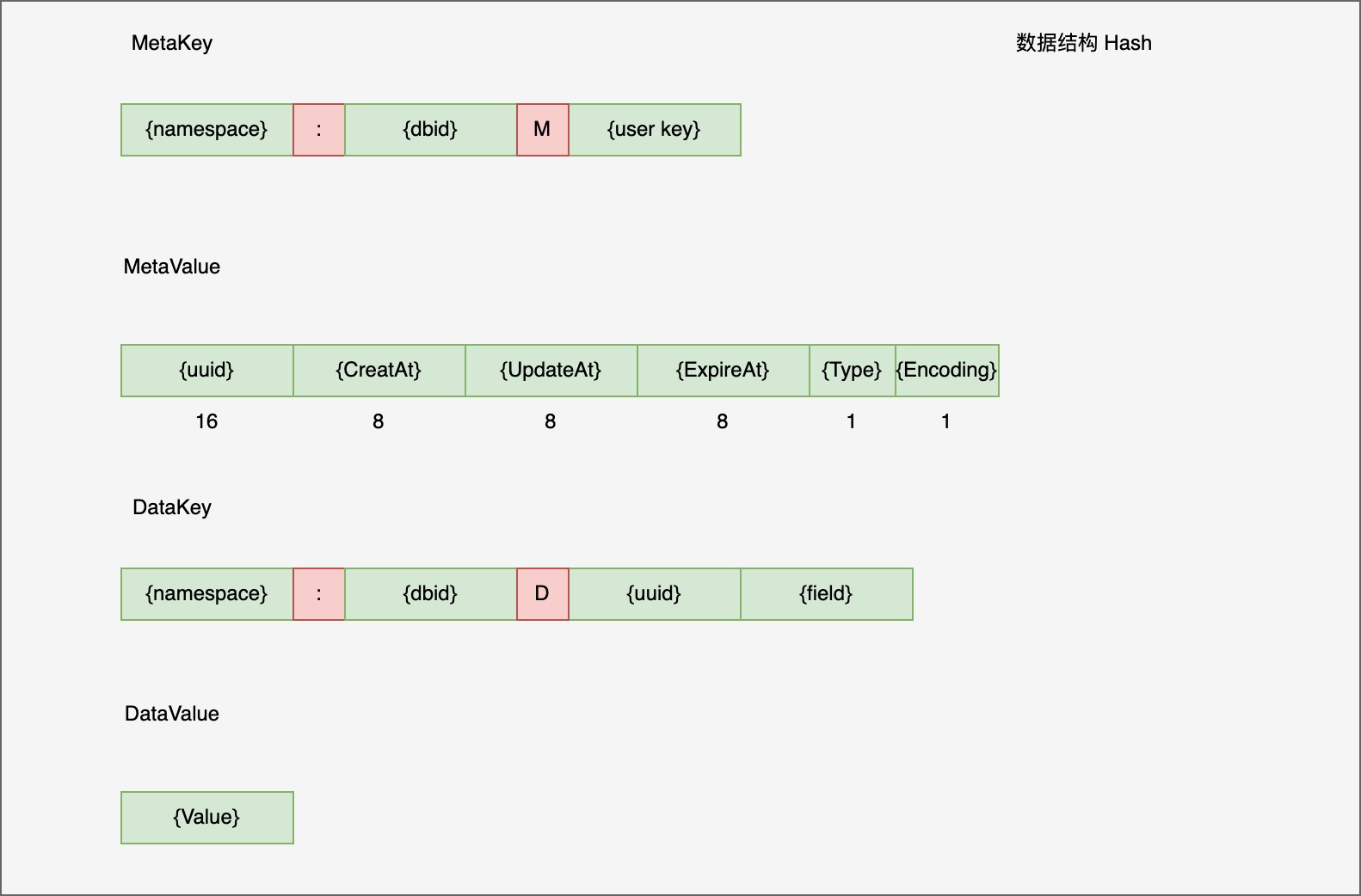
注意这里 hash 的 MetaValue 并没有维护成员 Len 信息,所以当 HLEN 时要遍历 range 整个 data key 空间,为什么这么做呢?
titan 作者说 hash 写并发时会有大量的事务冲突,所以选择不维护。后来他们提出一个方案,对 MetaKey 拆分成多个 slot,尽可能减少冲突,同时还能提高 HELN 性能,不过后来也没实现
List
List 有两种结构,一个是 ziplist, value 是用 pb 将多个元素编码在一起, 另外一个是 linkedlist. 当前实现没看到 ziplist 到 linkedlist 的转换,其实对于持久化存储来说,只用 linkedlist 足够了
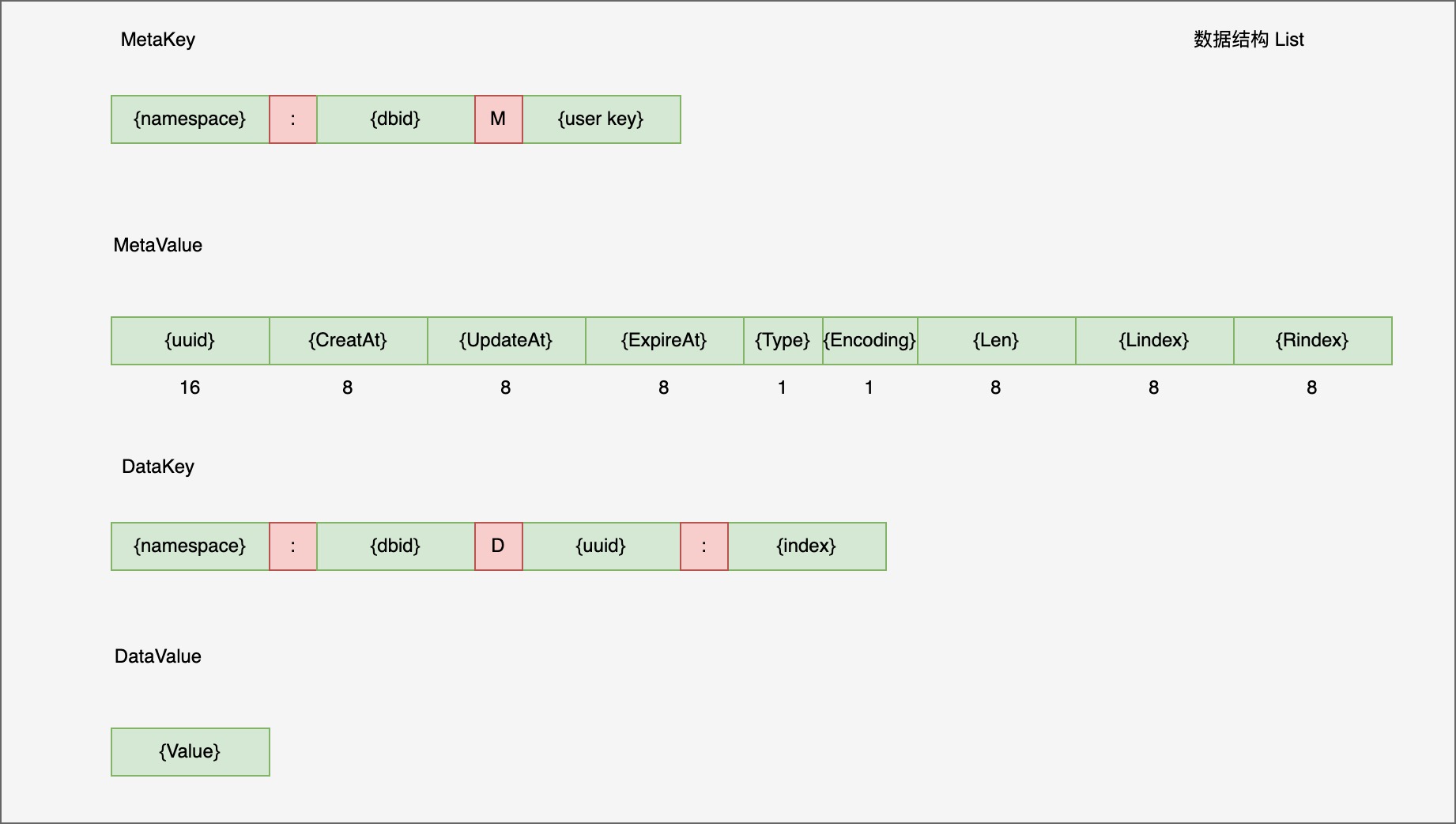
MetaValue 后 24 字节分别维护了 len, lindex 和 rindex, 其中 index 类型是 float64, 为什么不是 int64 类型呢?
原因在于对于 Linsert 操作,如果插入 (2, 3) 之间,那么会失败,但是用 float64 大概率会成功,但是考滤 float64 也有精度问题,存在失败的概率
1 | // calculateIndex return the real index between left and right, return ErrPerc= |
DataKey 编码 index 信息,DataValue 就是值
事务冲突
由于 titan 整体都是小事务,所以对于 tikv 事务开启了 1PC 和 AsyncCommit, 来提高整体吞吐量。对于冲突的事务,titan 尽可能重试保证执行成功
关于 affinity 亲缘性问题,titan 想将一个类型的 key 尽可能放到一个 tikv 实例中,当前没有实现,很难,不好搞。可以说 tikv 减少了持久化 kv 开发难度,也束缚了灵活性
删除 GC
Delete 时,删除 MetaKey,如果存在 TTL 那么删除 ExpireKey, 对于非 String,将 DataKey 扔到 sys namespace 中
$sys{namespace}:{sysDatabaseID}:GC:{datakey}
后台 doGC 调用 gcDeleteRange 慢慢删除,由于 DataKey 中存在 uuid, 基本不会重复,不影响用户重新创建相同 key
Flushdb 操作也非常重,理论上可以给所有 key 编码时带上 version, 这样可以快速 flush 快速回滚
运维周边
代码开源只是第一步,周边生态建设好用的人才多。目前看 tikv 运维 pingcap 有很多文档,基本够用了,做好参数上的调优
监控,故障处理,做好 chaos 故障注入测试
数据一致性校验,异构同步 redis 等等目前看都是缺失的
小结
目前 titan 的状态离真正 production ready 还差若干个 P0 故障,OOM 内存被打爆,spike 流量把集群打跨
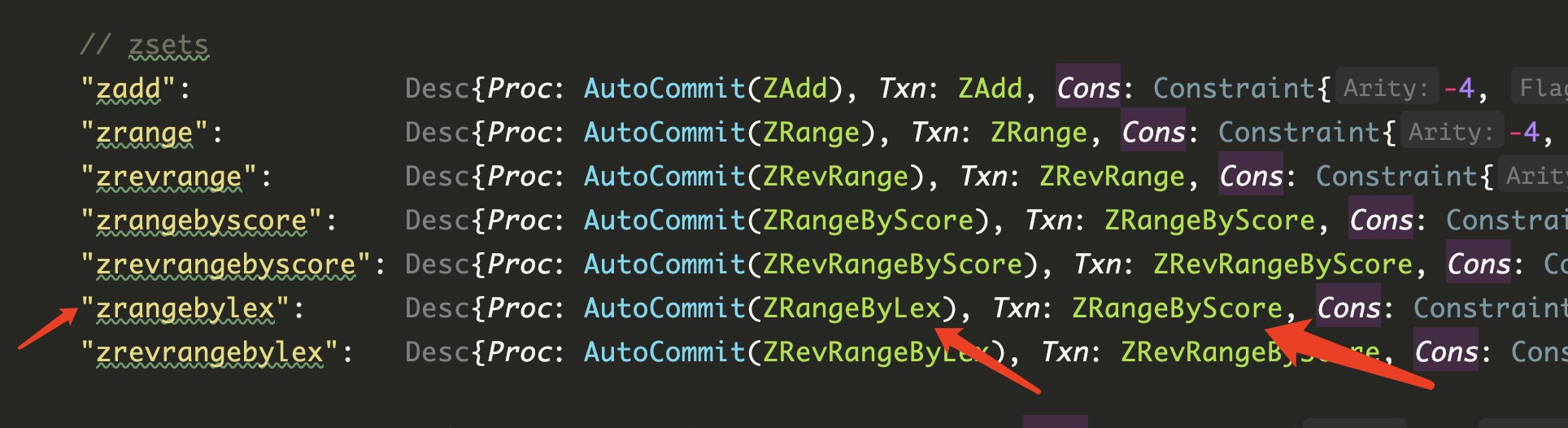
代码还有些书写瑕疵,想要用的同学,有能力二次开发的做好集群压测,故障注入,限流,千万不要急于上线,随时做好回滚的准备
分享知识,长期输出价值,这是我做公众号的目标。同时写文章不容易,如果对大家有所帮助和启发,请帮忙点击在看,点赞,分享 三连
