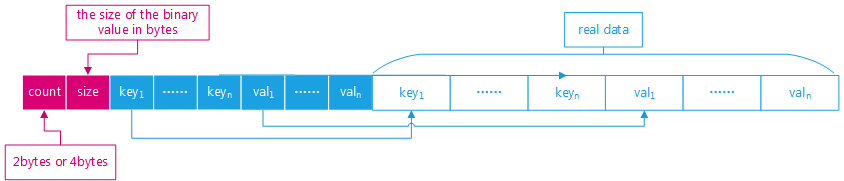
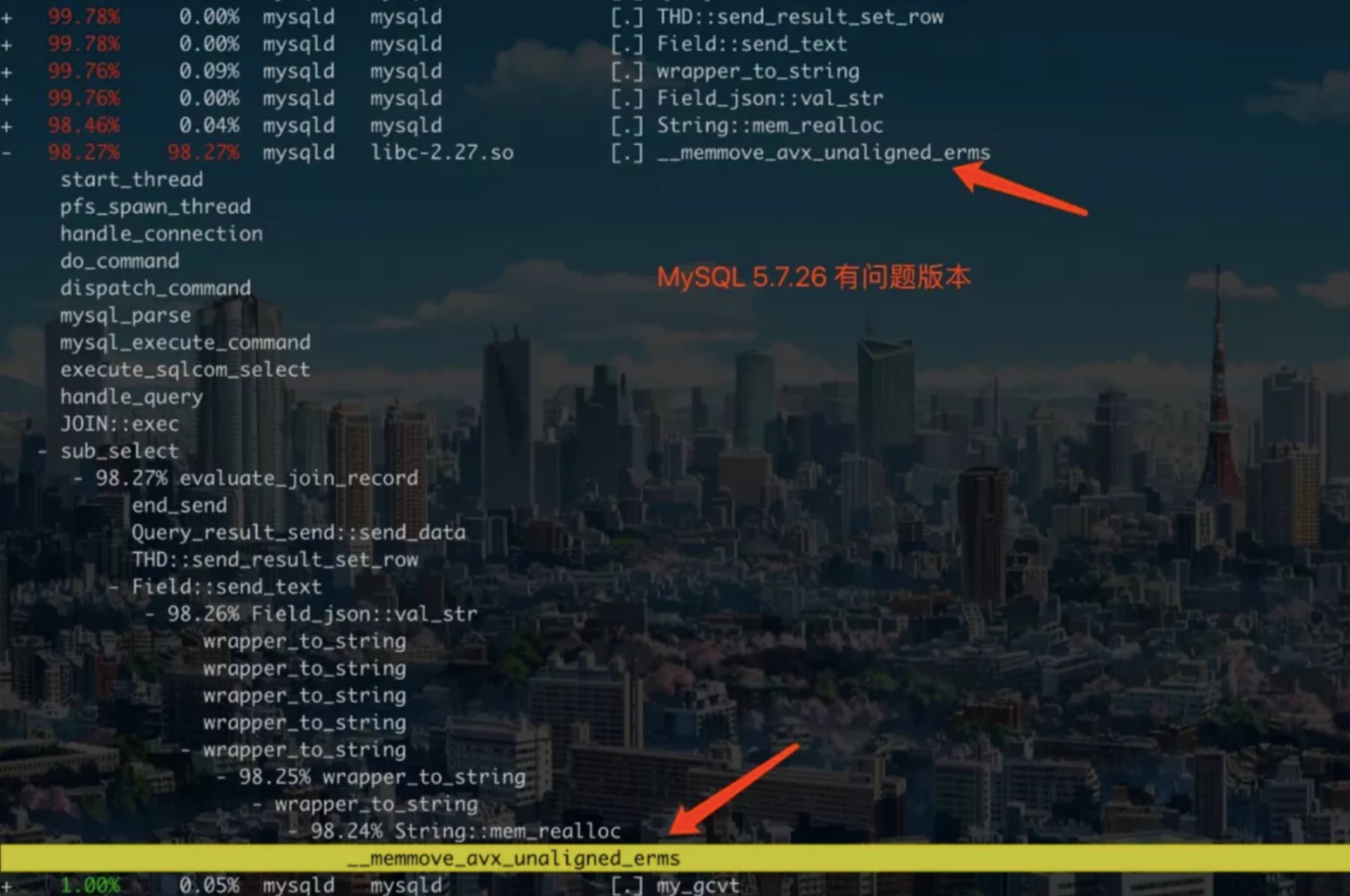
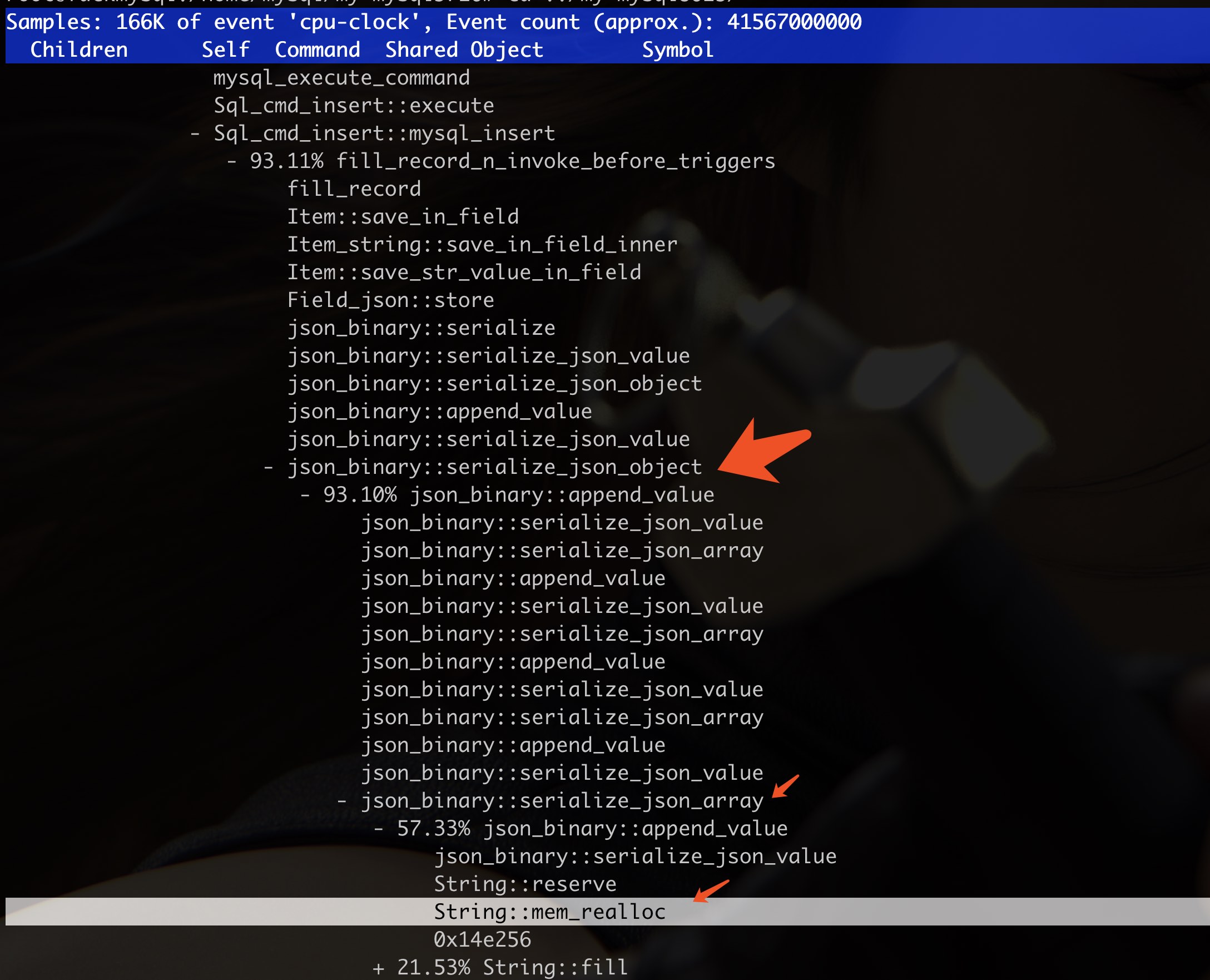
Bug#23031146: INSERTING 64K SIZE RECORDS TAKE TOO MUCH TIME
If a JSONvalue consists of a large sub-document which is wrapped in many levels ofJSON arrays or objects, serialization of the JSONvalue may take a very long timeto complete.
This is caused by how the serialization switches between the small storage format (used by documents that need less than 64KB) and the largestorageformat. When it detects that the largestorageformat has to be used, it redoes the serialization of the current sub-document using the largeformat. But this re-serialization has to be redone again when the parent of the sub-document is switched from small formattolargeformat. For deeply nested documents, the inner parts end up getting re-serializing again and again.
This patch changes how the switch between the formats is done. Instead of starting with re-serializing the inner parts, it now starts with the outer parts. If a sub-document exceeds the maximum size for the small format, we know that the parent document will exceed it and need to be re-serialized too. Re-serializing an inner document is therefore a waste oftimeif we haven't already expanded its parent. By starting with expanding the outer parts of the JSON document, we avoid the wasted work and speed up the serialization.